


En muchos equipos técnicos, existen tareas que se repiten cada semana o cada mes: generación de reportes, validación de datos, procesamiento de facturas, envíos de correos automáticos… Son necesarias, pero consumen tiempo y están expuestas a errores humanos. En este post, te muestro cómo puedes automatizar cualquier flujo recurrente usando una arquitectura flexible basada en Python, Flask, SQLAlchemy y Jinja2.
Spoiler: con solo definir una receta .yml y unas plantillas .j2, podrás lanzar un flujo desde una API y dejar que un demonio lo orqueste paso a paso.
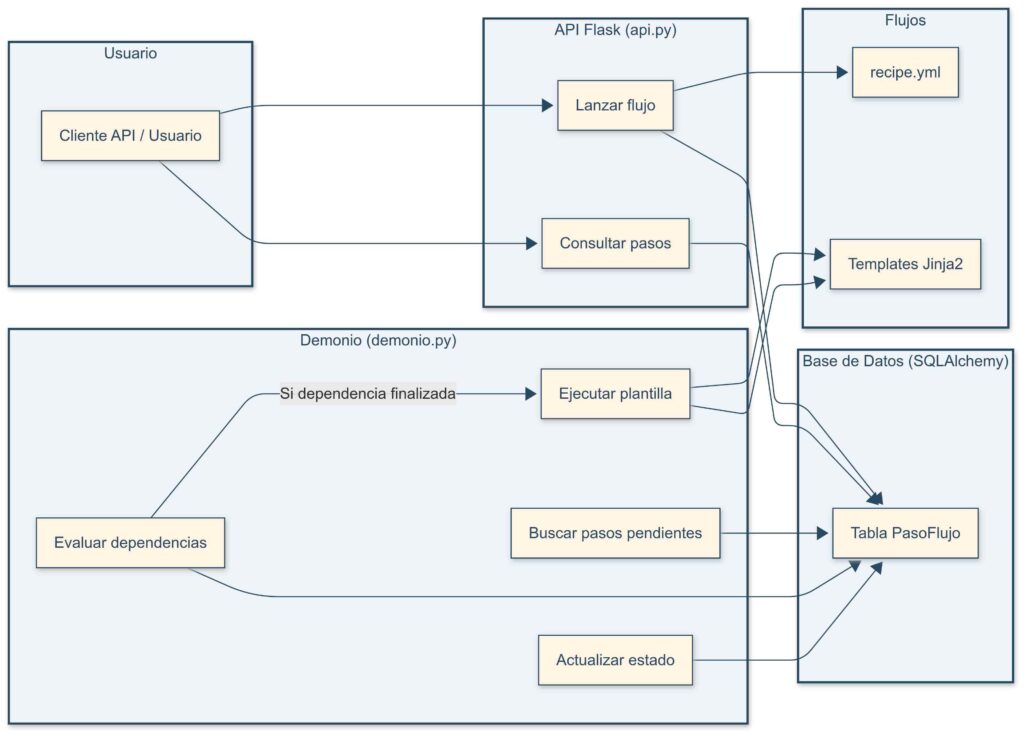
Estructura general del sistema
La arquitectura base del proyecto tiene esta estructura:
automatizacion-flujos/ ├── app/ │ ├── main.py │ ├── api.py # API REST con Flask │ ├── demonio.py # Ejecuta pasos según sus dependencias │ ├── flujos/ │ │ ├── reportes/ │ │ │ ├── recipe.yml │ │ │ └── templates/ │ │ │ ├── validacion_datos.j2 │ │ │ ├── procesamiento_datos.j2 │ │ │ └── generacion_informe.j2 │ ├── models.py │ ├── utils.py ├── requirements.txt
Cada carpeta dentro de /flujos, representa un tipo de flujo. Al lanzar uno desde la API, se crean registros en base de datos para cada paso, y un demonio se encarga de ejecutarlos en orden, según sus dependencias.

Librerías necesarias
El archivo requirements.txt contiene las librerías necesarias para la ejecución del proyecto:
Flask==3.0.3 Flask-RESTX==1.3.0 Flask-SQLAlchemy==3.1.1 Jinja2==3.1.2 PyYAML==6.0.2
Para instalar las dependencias ejecuta el comando pip install -r requirements.txt (Se requiere tener instalado pip). Las versiones de estas dependencias son compatibles con la versión de python 3.13.
Define tu flujo con YAML
app/flujos/reportes/recipe.yml -
pasos:
- nombre: validacion_datos
plantilla: validacion_datos.j2
- nombre: procesamiento_datos
plantilla: procesamiento_datos.j2
depende_de: validacion_datos
- nombre: generacion_informe
plantilla: generacion_informe.j2
depende_de: procesamiento_datos
Cada paso puede depender de otro. Esto permite construir flujos secuenciales y condicionales fácilmente.
app/flujos/templates/validacion_datos.j2 – Primer paso del flujo
# Simulación de validación
fecha: {{ cuerpo_global.fecha }}
cantidad: {{ cuerpo_global.cantidad_paginas }}
✅ Datos validados para el informe del {{ cuerpo_global.fecha }}
app/flujos/templates/procesamiento_datos.j2 – Segundo paso del flujo
# Simulación de procesamiento
📊 Procesando datos del informe para la fecha {{ cuerpo_global.fecha }}...
Procesamiento completado correctamente.
app/flujos/templates/generacion_informe.j2 – Tercer paso del flujo
# Simulación de generación del informe
📝 Informe generado
Fecha: {{ cuerpo_global.fecha }}
Páginas: {{ cuerpo_global.paginas }}
Resumen: {{ cuerpo_global.resumen }}
Desarrollando la solución paso a paso
Ahora que tienes una receta YAML definida, vamos a crear la lógica necesaria para almacenar los pasos en base de datos:
app/models.py – Modelo de la base de datos
from flask_sqlalchemy import SQLAlchemy
from datetime import datetime
db = SQLAlchemy()
class PasoFlujo(db.Model):
id = db.Column(db.Integer, primary_key=True)
id_flujo = db.Column(db.String(64), nullable=False)
tipo_flujo = db.Column(db.String(64), nullable=False)
nombre_paso = db.Column(db.String(64), nullable=False)
plantilla = db.Column(db.String(128), nullable=False)
cuerpo = db.Column(db.JSON, nullable=False)
depende_de = db.Column(db.String(64), nullable=True)
estado = db.Column(db.String(32), default='pendiente')
fecha_alta = db.Column(db.DateTime, default=datetime.utcnow)
fecha_estado = db.Column(db.DateTime, default=datetime.utcnow)
app/utils.py – Cargar receta y crear pasos
import yaml
from pathlib import Path
from models import PasoFlujo, db
from datetime import datetime
def cargar_recipe_y_crear_pasos(carpeta_flujo, cuerpo_global, id_flujo):
ruta_path = Path(__file__).resolve().parent / "flujos" / carpeta_flujo / "recipe.yml"
try:
with open(ruta_path, 'r', encoding='utf-8') as f:
receta = yaml.safe_load(f)
except FileNotFoundError as e:
raise FileNotFoundError(f"No se encontró el archivo de recipe en: {ruta_path}") from e
pasos_creados = []
for paso in receta['pasos']:
nuevo_paso = PasoFlujo(
id_flujo=id_flujo,
tipo_flujo=carpeta_flujo,
nombre_paso=paso['nombre'],
plantilla=paso['plantilla'],
cuerpo=cuerpo_global,
depende_de=paso.get('depende_de'),
estado='pendiente',
fecha_alta=datetime.now(),
fecha_estado=datetime.now()
)
db.session.add(nuevo_paso)
pasos_creados.append(nuevo_paso)
db.session.commit()
return pasos_creados
A continuación vamos a exponer la API REST para poder ejecutar los pasos correspondientes.
app/api.py – API REST para lanzar y consultar flujos
import uuid
from flask import request
from flask_restx import Resource, Namespace, fields
from models import PasoFlujo
from utils import cargar_recipe_y_crear_pasos
api_bp = Namespace('flujos', description='Gestión de flujos automatizados')
# Definimos el modelo para la documentación Swagger
modelo_flujo = api_bp.model('LanzarFlujo', {
'carpeta_flujo': fields.String(required=True, description='Nombre de la carpeta del flujo (ej. "reportes")'),
'cuerpo_global': fields.Raw(required=True, description='Diccionario con los parámetros que se pasarán a las plantillas')
})
modelo_paso = api_bp.model('Paso', {
'nombre_paso': fields.String,
'estado': fields.String,
'depende_de': fields.String,
'fecha_estado': fields.String
})
modelo_flujo_detalle = api_bp.model('FlujoDetalle', {
'id_flujo': fields.String,
'pasos': fields.List(fields.Nested(modelo_paso))
})
@api_bp.route('/')
class LanzarFlujo(Resource):
@api_bp.expect(modelo_flujo)
@api_bp.response(201, 'Flujo creado')
def post(self):
data = request.get_json()
carpeta_flujo = data.get("carpeta_flujo")
cuerpo_global = data.get("cuerpo_global")
id_flujo = str(uuid.uuid4())
pasos_creados = cargar_recipe_y_crear_pasos(
carpeta_flujo=carpeta_flujo,
cuerpo_global=cuerpo_global,
id_flujo=id_flujo
)
return {
"id_flujo": id_flujo,
"pasos_creados": [p.nombre_paso for p in pasos_creados]
}, 201
@api_bp.route('/<string:id_flujo>')
class ObtenerFlujo(Resource):
@api_bp.marshal_with(modelo_flujo_detalle)
def get(self, id_flujo):
pasos = PasoFlujo.query.filter_by(id_flujo=id_flujo).order_by(PasoFlujo.fecha_alta).all()
return {
'id_flujo': id_flujo,
'pasos': pasos
}
@api_bp.route('')
class ListarFlujos(Resource):
def get(self):
flujos = PasoFlujo.query.all()
agrupado = {}
for paso in flujos:
flujo = agrupado.setdefault(paso.id_flujo, [])
flujo.append({
"nombre_paso": paso.nombre_paso,
"estado": paso.estado,
"depende_de": paso.depende_de,
"fecha_estado": paso.fecha_estado.isoformat() if paso.fecha_estado else None
})
return agrupado, 200
Por último, crea el demonio que orquesta la ejecución y las dependencias.
app/demonio.py – Orquestador de flujos
import time
from pathlib import Path
from models import db, PasoFlujo
from main import create_app
from datetime import datetime
from jinja2 import Template
# Inicializar la app para tener contexto
app = create_app()
def renderizar_template(template_path, contexto):
"""Renderiza una plantilla Jinja2 con el contexto dado."""
with open(template_path, "r") as file:
content = file.read()
template = Template(content)
return template.render(**contexto)
def ejecutar_paso(paso: PasoFlujo):
print(f"🟡 Ejecutando paso: {paso.nombre_paso} del flujo {paso.id_flujo}")
ruta_template = Path(__file__).resolve().parent / "flujos" / paso.tipo_flujo / "templates" / paso.plantilla
try:
contenido_resuelto = renderizar_template(ruta_template, {"cuerpo_global": paso.cuerpo})
# ✅ Guardamos el contenido resuelto directamente en el paso
paso.cuerpo["contenido_resuelto"] = contenido_resuelto
paso.estado = "finalizado"
paso.fecha_estado = datetime.now()
db.session.commit()
print(f"▶️ Contenido resuelto del paso:\n{contenido_resuelto}")
print(f"✅ Paso {paso.nombre_paso} finalizado.\n")
except Exception as e:
paso.estado = "error"
paso.fecha_estado = datetime.now()
paso.cuerpo["error"] = str(e)
db.session.commit()
print(f"❌ Error al ejecutar paso {paso.nombre_paso}: {e}")
def dependencia_finalizada(paso: PasoFlujo):
if not paso.depende_de:
return True
paso_previo = PasoFlujo.query.filter_by(
id_flujo=paso.id_flujo,
nombre_paso=paso.depende_de
).first()
return paso_previo and paso_previo.estado == "finalizado"
def ejecutar_demonio():
print("🔁 Iniciando demonio de ejecución de flujos...")
while True:
with app.app_context():
pasos_pendientes = PasoFlujo.query.filter_by(estado="pendiente").all()
for paso in pasos_pendientes:
if dependencia_finalizada(paso):
paso.estado = "en_curso"
paso.fecha_estado = datetime.now()
db.session.commit()
ejecutar_paso(paso)
# Esperar 10 segundos antes de revisar de nuevo
time.sleep(10)
if __name__ == "__main__":
ejecutar_demonio()
app/main.py – Punto de ejecución de la aplicación
from flask import Flask
from flask_restx import Api
from models import db
from api import api_bp
def create_app():
app = Flask(__name__)
app.config["SQLALCHEMY_DATABASE_URI"] = "sqlite:///flujos.db"
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
db.init_app(app)
api = Api(app, title="API de Automatización de Flujos", version="1.0", doc="/swagger")
api.add_namespace(api_bp, path="/api/flujos")
with app.app_context():
db.create_all()
return app
if __name__ == "__main__":
app = create_app()
app.run(debug=True)
Lanza tu flujo desde la API
Una vez implementado todo el backend, puedes lanzar flujos desde la API REST.
Ejecuta la aplicación y el demonio en dos consolas diferentes para que puedas ver las ejecuciones de cada uno por separado:
python app/demonio.py


El demonio se ejecuta cada diez segundos de forma recurrente a la espera de encontrar registros en estado pendiente.
python app/main.py
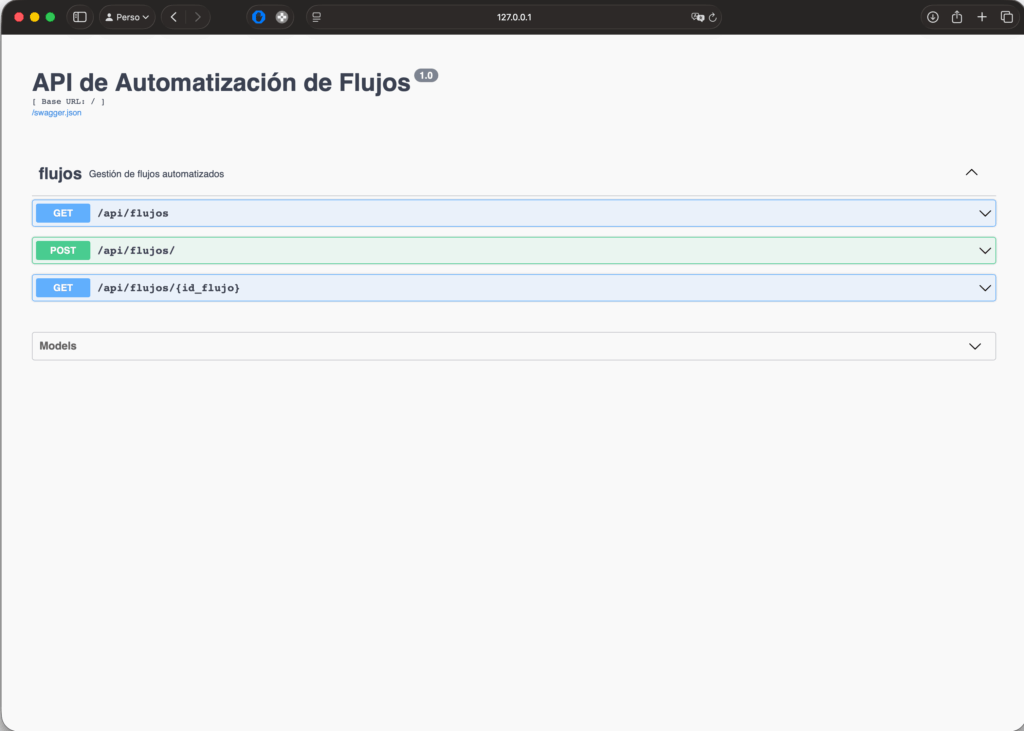
En el navegador introduce la siguiente url para acceder al Swagger de la aplicación que acabas de crear.
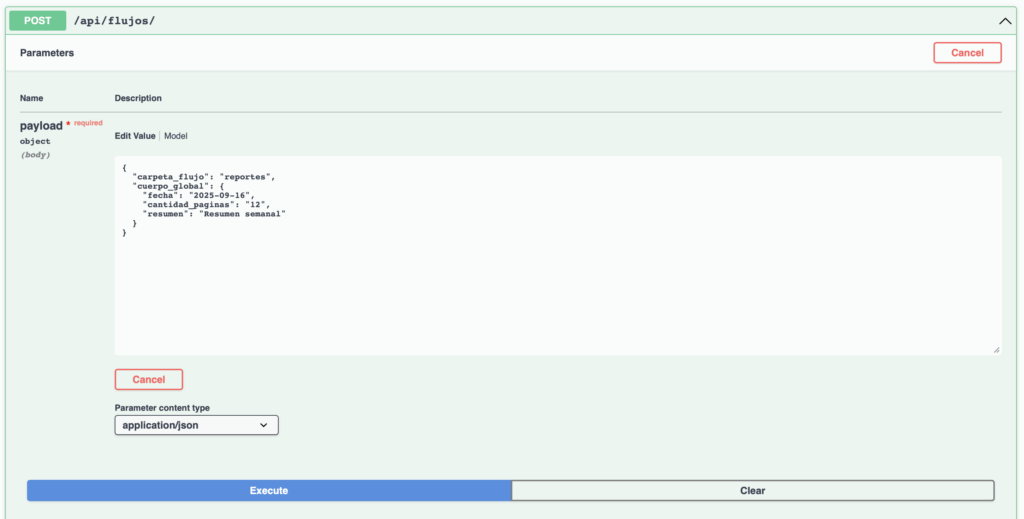
Ejecutamos el endpoint POST /api/flujos para crear el flujo con el JSON de ejemplo:
{
"carpeta_flujo": "reportes",
"cuerpo_global": {
"fecha": "2025-01-01",
"cantidad_paginas": "12",
"resumen": "Resumen semanal"
}
}
Esta es la respuesta esperada por parte de la API:
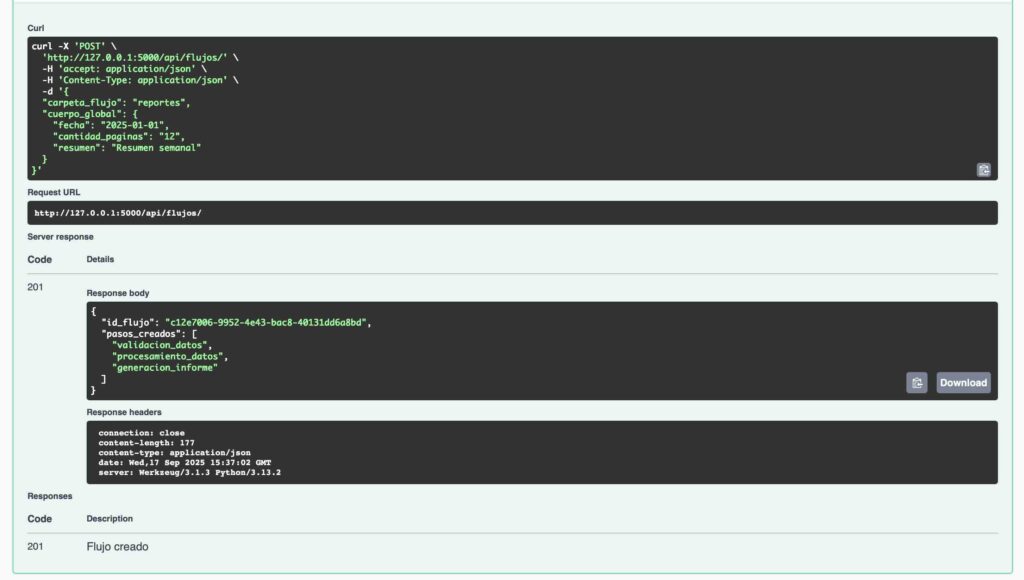
Esto crea tres registros en la base de datos, uno por paso. Cada registro incluye:
- UUID.
- Tipo de flujo.
- El contenido con la parametrización de la plantilla correspondiente.
- Nombre del paso.
- Paso del que depende (si aplica).
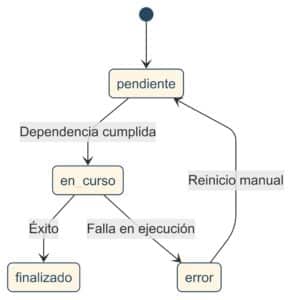
- Estado:
pendiente, en_curso, finalizado, error

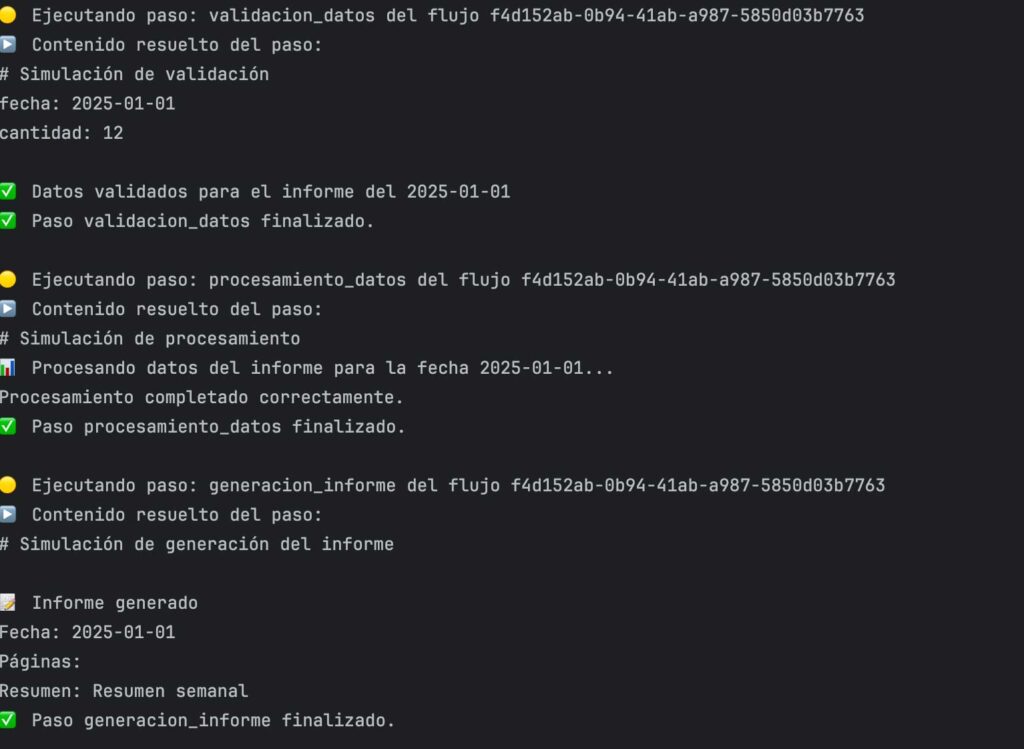
Con esto ya hemos creado el primer flujo. Y solo nos queda esperar que el demonio recupere los pasos y los ejecute de forma sucesiva:

Visualiza los flujos creados
Puedes consultar un flujo completo desde la API en GET /api/flujos/{uuid_flujo}

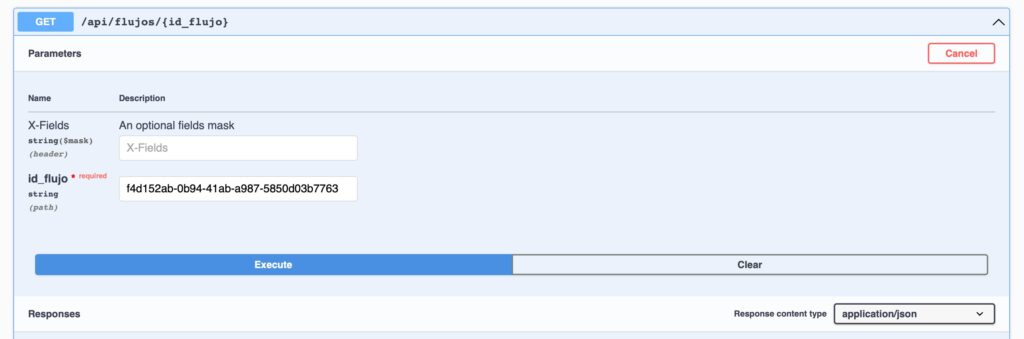
Y verás un JSON con todos los pasos encadenados, sus estados y dependencias. También puedes consultar todos los flujos agrupados:

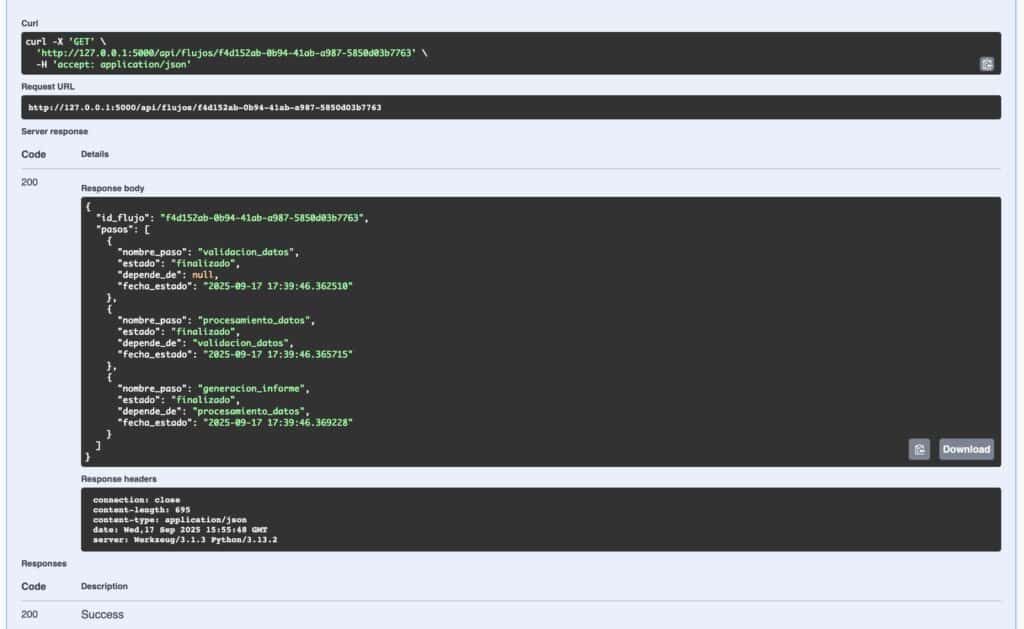
Conclusión y posibles siguientes pasos
Este enfoque te permite construir flujos reutilizables, parametrizados y seguros. Puedes expandirlo con:
- UI para lanzar y monitorear flujos.
- Dashboard con métricas.
- Soporte para tareas asíncronas o por cron.
- Logging y alertas.
- Integración con otros servicios externos.
Si tienes tareas repetitivas que aún haces a mano… es hora de automatizarlas.
¡Sigue aprendiendo sobre automatización y más mundo tech en nuestras redes sociales!