


En este artículo hacemos una introducción al análisis de grandes volúmenes de datos utilizando Apache Hadoop y Apache Spark, dos de las herramientas de Big Data más potentes en la actualidad. ¡Vamos allá!
Qué vas as ver en esta entrada
Programación paralela
Debido a que estamos en una época de auge de la transformación digital, todo es susceptible de poder utilizarse como dato. Además, cada vez los sistemas tecnológicos tienen mayor capacidad. Esto hace que la cantidad de datos de los que se disponen sea masiva, lo que da lugar al Big Data, que se caracteriza por las denominadas 4 Vs:
- Volumen: se produce una cantidad inmensa de datos (generados por aplicaciones operacionales, interacciones de los usuarios, datos externos…).
- Velocidad: el ritmo de entrada de datos es cada vez mayor y es continuo. De manera que cada segundo la cantidad de datos se incrementa masivamente.
- Variedad: las fuentes de datos son muy amplias, desde bases de datos operacionales, a redes sociales o páginas HTML.
- Veracidad: no todos los datos son comprobables, y solo hay que tener en cuenta los correctos.
Los algoritmos secuenciales en una misma máquina no son la mejor opción para analizar este volumen de información, debido a que serían demasiado ineficientes y costosos. Estos algoritmos se basan en la escalabilidad vertical, es decir, conseguir mejorar el rendimiento añadiendo más recursos a un mismo nodo.
La aproximación para poder escalar en ecosistemas de Big Data es utilizar algoritmos paralelos. Para que varias máquinas o nodos puedan realizar tareas más simples, pero de manera simultánea, para conseguir abordar todo el análisis como un todo. Estos algoritmos se basan en la escalabilidad horizontal, es decir, conseguir mejorar el rendimiento añadiendo más nodos.
Paradigma MapReduce
Con el fin de poder realizar algoritmos paralelos en sistemas con grandes cantidades de datos surgió el paradigma MapReduce. Este paradigma se basa en dos principales funciones:
- Map: en cada nodo, obtiene los datos del disco en forma clave-valor, y realiza una transformación de estos en forma clave-valor.
- Reduce: realiza las tareas de agregación de las salidas generadas por map.
Ejemplo de aplicación del paradigma MapReduce
Vamos a ver un ejemplo sencillo del paradigma MapReduce:
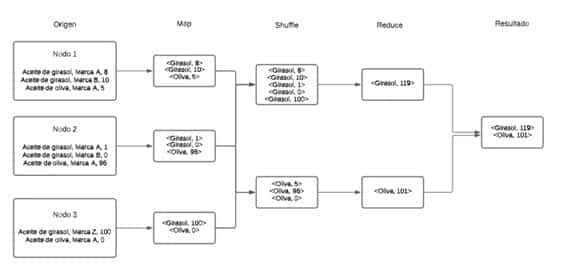
Estado inicial
A partir de 3 fuentes de datos que contienen el stock de aceites de un supermercado, se quiere obtener el stock de cada tipo de aceite:
- Nodo 1:
Aceite de girasol, Marca A, 8.
Aceite de girasol, Marca B, 10.
Aceite de oliva, Marca A, 5 .
- Nodo 2:
Aceite de girasol, Marca A, 1.
Aceite de girasol, Marca B, 0.
Aceite de oliva, Marca A, 96.
- Nodo 3:
Aceite de girasol, Marca Z, 100.
Aceite de oliva, Marca A, 0.
Operación map
En este caso, tras aplicar la operación map, se obtendrían los siguientes pares clave-valor (la clave consiste en el tipo de aceite y el valor en el número de unidades):
- Nodo 1: <Girasol, 8>, <Girasol, 10>, <Oliva, 5>
- Nodo 2: <Girasol, 1>, <Girasol, 0>, <Oliva, 96>
- Nodo 3: <Girasol, 100>, <Oliva, 0>
Operación reduce
Y, tras aplicar la operación reduce, se realizaría la suma por clave de cada uno de los tipos:
- <Girasol, 119>
- <Oliva, 101>
Apache Hadoop
Apache Hadoop es la implementación de código abierto de MapReduce.
¿Cómo aplica MapReduce Apache Hadoop?
Apache Hadoop lleva a cabo MapReduce de la siguiente manera:
- Los ficheros se distribuyen de una manera similar entre cada uno de sus sistemas de almacenamiento (habitualmente HDFS).
- Todos los nodos realizan la misma tarea map. Es decir, no hay ninguna diferencia entre los diferentes nodos, todos saben realizar la misma tarea sobre los mismos ficheros.
- Los resultados de la operación map de cada uno de los nodos se ordenan por clave, mediante una operación denominada shuffling. Los pares de clave valor con la misma clave se envían a un mismo nodo, para aplicar la operación reduce.
- Se van enviando los resultados de map de manera constante, dando lugar a particiones que van siendo procesadas por los nodos reduce.
- Una vez finalizan los nodos reduce, se almacena la salida en disco.
Desventajas de Apache Hadoop
Aunque era el estado del arte hace algunos años, se han encontrado algunos inconvenientes: como la necesidad de adaptar todas las soluciones a la división entre tareas map y reduce, que no siempre es sencillo, y al utilizar lecturas y escrituras en disco hace que no sea demasiado rápido.
Ejemplo de funcionamiento de Hadoop

Apache Spark
Apache Spark es un sistema para procesar datos distribuidos de una manera escalable horizontal y no requiriendo tanta complejidad conceptual como con el ecosistema MapReduce. Surgió para solventar los problemas que se vieron en Apache Hadoop, pero no siempre es lo óptimo para todos los casos de uso.
RDD en Spark
La pieza fundamental en la que Spark se basa para realizar la paralización se denomina RDD o Resilient Distributed Dataset. Se trata de una colección de objetos que es inmutable (es decir, de solo lectura una vez creada), distribuida, puede almacenarse en la caché y contiene una lista de referencias a particiones de los datos en el sistema.
¿Cómo hace particiones Spark?
Es Spark el encargado de realizar estas particiones y lo hace de la siguiente manera:
- Hay un tamaño de bloque predefinido, habitualmente 64 o 128MB.
- Ante ficheros más grandes, Spark realiza las particiones con el tamaño de bloque predefinido, y se asignan en base a criterios como el tráfico entre nodos o dónde están situados físicamente los datos.
¿Cómo se pueden cargar los RDD en Apache Spark?
- Utilizando la función parallelize, para crear un objeto paralelo a partir de una colección.
- A partir de fuentes externas de ficheros, como Amazon S3.
- Al transformar un RDD existente.
Operaciones para los RDD
Hay dos tipos de operaciones que se pueden aplicar a los RDD: transformaciones o acciones.
- En cuanto a las transformaciones, se utilizan para obtener un RDD a partir del original, para poder realizar las acciones necesarias. Entre otras, se puede utilizar Map, FlatMap, MapPartition, Filter, Sample o Union. Todas las transformaciones son lazy, es decir, solo se realizan cuando se necesiten utilizar.
- Por otra parte, las acciones se aplican una vez se han hecho las transformaciones, para obtener los resultados deseados. Entre otras: reduce, collect, count, first, foreach o countByKey.
Las operaciones pueden ser de dos tipos, según si necesitan estar en la misma partición o no:
- Narrow: solo se deben utilizar los datos de una misma partición. Por ejemplo: filter, sample o flatMap.
- Wide: se necesita utilizar los datos de más particiones. Por lo que antes de realizar la operación hay que unir todos los datos de las particiones. Por ejemplo: groupByKey y reduceByKey.
¿Cómo realiza las operaciones Spark?
A través de un grafo DAG (Directed Acyclic Graph o grafo dirigido acíclico), se determina el orden de las operaciones que se hayan definido. Esto es debido a que no siempre se van a ejecutar en el orden en el que se han definido, sino en el óptimo para Spark.
Primero se van a realizar las operaciones narrow (las que se pueden hacer en una misma partición) y después se harán las operaciones wide, manteniendo el orden determinado por Spark tras el análisis del grafo DAG.
Ejemplo de operaciones de Spark
# Cargamos sesión Spark
sc = SparkContext('local')
spark = SparkSession(sc)
# Leemos el fichero (file1.csv)
oilDf = spark.read.csv("file1.csv", header='true', inferSchema = 'true')
# Sumamos la cantidad por producto
oilDf.groupBy("Producto").sum("Cantidad").collect()
Conclusión
En este artículo nos hemos aproximado al análisis de datos masivos a través de Apache Hadoop y Apache Spark, dos tecnologías fundamentales en Big Data en la actualidad. Concretamente, hemos revisado los conceptos de programación paralela y paradigma MapReduce y hemos diseccionado el funcionamiento de Hadoop y Spark a través de un ejemplo en el que hemos calculado el stock de aceites en un supermercado.
Descubre más sobre cómo trabajar con grandes volúmenes de datos en nuestro canal de YouTube. ¡Suscríbete!