


Los modelos de Inteligencia Artificial están en boca de todo el mundo desde la irrupción de ChatGPT. Sin embargo; en lo que se refiere a entornos corporativos, estas herramientas no suelen tener el contexto interno (APIs, documentación, manuales, procesos, etc.) para responder bien a las cuestiones de los usuarios.
La arquitectura RAG (Retrieval-Augmented Generation) resuelve este problema aportando bases externas de conocimiento. En lugar de aplicar fine-tuning a un LLM desde cero, RAG hace algo más directo: recupera los fragmentos relevantes de tu documentación y se añaden como contexto antes de generar la respuesta.
Algunos de los beneficios que ofrece la arquitectura RAG:
- Eficiente en coste de implementación, ya que no requiere entrenar modelos desde cero.
- Acceso a la información específica de un dominio.
- Reducción del riesgo de alucinaciones.
- Mejora en la confianza de los usuarios al recibir respuestas fundamentadas.
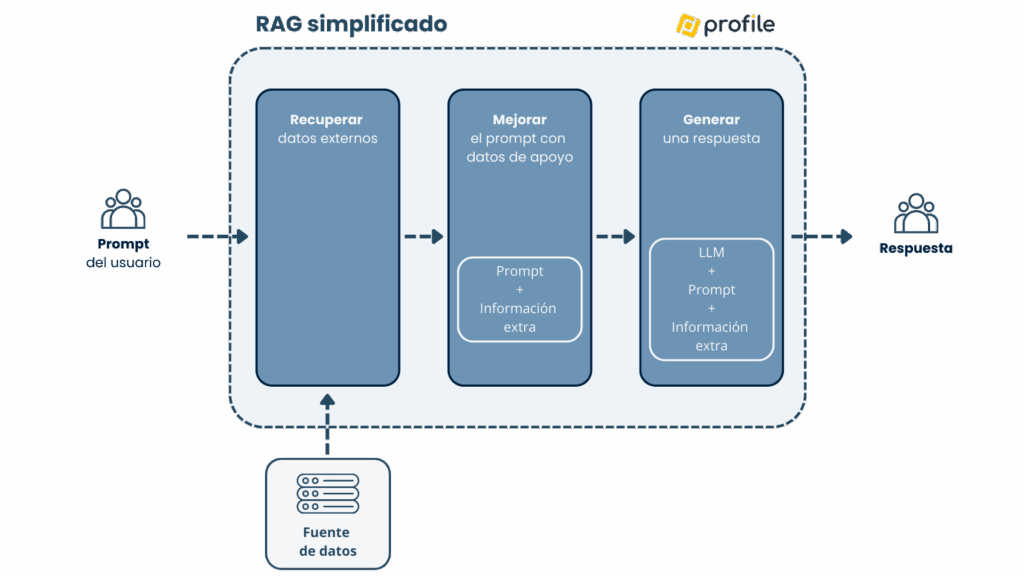
A lo largo de este post vamos a implementar un ejemplo de cómo crear un chatbot con RAG e IA generativa paso a paso, desde cero. Para ello, vamos a emplear las siguientes herramientas dentro del ecosistema Python:
- LangChain: para carga, fragmentación y orquestación documental.
- Embeddings de Hugging Face: para vectorizar los textos.
- FAISS: como índice vectorial persistente.
- Streamlit: para una interfaz de chat sencilla.
Comenzaremos con la base común de la que parte cualquier proyecto que involucra el aprendizaje automático: los datos.
Qué vas as ver en esta entrada
Preparando los datos
Una vez creado un proyecto en blanco, vamos a obtener una base de documentación de la plataforma de pagos Stripe, disponible en el repositorio stripe_docs_markdown. Colocamos los ficheros dentro de un directorio docs para poder ampliar el corpus en el futuro.
docs/
stripe/
billing/
connect/
...
Indexar la documentación (embeddings + FAISS)
Antes de hablar de los modelos generativos, necesitamos preparar el conocimiento. Aquí entran los embeddings:
- Un embedding es un vector numérico que representa el significado de un texto (frase/párrafo/chunk) en un espacio semántico.
- Si dos textos significan algo parecido, sus embeddings tienden a estar cerca.


En el contexto de RAG, los documentos (sean de tipo texto, imágenes, audio…) se convierten en vectores utilizando modelos de embeddings, posteriormente se almacenan en una base de datos vectorial y se recuperan según su similitud con la consulta del usuario.
Para este proyecto, vamos a utilizar FAISS como índice de datos vectorial, así como LangChain para tratar la colección de documentos.
Dependencias y carga de datos
En general, para todo el proyecto, necesitaremos las siguientes dependencias:
# requirements.txt # Gestión de lenguaje natural y procesamiento de texto langchain==1.2.3 langchain-community==0.4.1 langchain-text-splitters==1.1.0 unstructured==0.18.27 unstructured[md] sentence-transformers==5.2.0 # FAISS para búsqueda eficiente de vectores y LangChain HuggingFace para integración de modelos faiss-cpu==1.13.2 langchain-huggingface==1.2.0 # Streamlit para la creación de aplicaciones web interactivas (chatbot) streamlit==1.52.2 # Ajuste de dependencias para compatibilidad torch==2.8.0
En este caso, los documentos están en formato Markdown, pero como mencionamos anteriormente podrían ser HTML, PDF o cualquier otro formato, LangChain tiene soporte para la gran mayoría.
El siguiente código leerá y procesará en fragmentos de 1000 caracteres cada documento (con cierto solapamiento para mantener contexto). Estos valores se pueden ajustar en función del tipo de documentación, pero con fragmentos demasiado grandes se pueden generar alucinaciones en las respuestas y con fragmentos muy pequeños se pierde el contexto local.
Finalmente, este script creará la base de datos vectorial con los embeddings de HuggingFace.
# data_loader.py
import os
import shutil
from langchain_community.document_loaders import DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
from langchain_community.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddings
# Rutas de configuración
DOCS_PATH = "./docs/"
FAISS_DB_PATH = "faiss_db"
# Configuración para el chunking de texto
TEXT_CHUNK_SIZE = 1000
TEXT_CHUNK_OVERLAP = 200
def main():
# Punto de entrada principal
documents = load_documents()
chunks = split_text(documents)
save_to_faiss(chunks)
def load_documents():
# Carga los documentos desde el directorio especificado
directory_loader = DirectoryLoader(DOCS_PATH, glob="**/*.md")
docs = directory_loader.load()
print(f"Cargados {len(docs)} documentos desde {DOCS_PATH}.")
return docs
def split_text(documents, chunk_size=TEXT_CHUNK_SIZE, chunk_overlap=TEXT_CHUNK_OVERLAP):
# Divide los documentos en chunks manejables
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
add_start_index=True,
)
chunks = text_splitter.split_documents(documents)
# Ejemplos de depuración
print(f"Documento dividido en {len(chunks)} chunks.")
print(f"Metadata del primer chunk: {chunks[0].metadata}")
print(f"Contenido del primer chunk: {chunks[0].page_content}")
return chunks
def save_to_faiss(chunks: list[Document]):
# Elimina la base de datos existente si existe
if os.path.exists(FAISS_DB_PATH):
shutil.rmtree(FAISS_DB_PATH)
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
print(f"Creando índice FAISS con {len(chunks)} chunks...")
# FAISS crea el índice directamente desde los documentos
db = FAISS.from_documents(chunks, embeddings)
# Guarda el índice localmente
db.save_local(FAISS_DB_PATH)
print(f"Almacenados {len(chunks)} chunks en {FAISS_DB_PATH}.")
if __name__ == "__main__":
main()
La salida producida por la ejecución de este script sería la siguiente:
Cargados 777 documentos desde ./docs/. Documento dividido en 10502 chunks. Metadata del primer chunk: {'source': 'docs\\stripe\\introduction\\api_reference.md', 'start_index': 0} Contenido del primer chunk: API Reference [...]
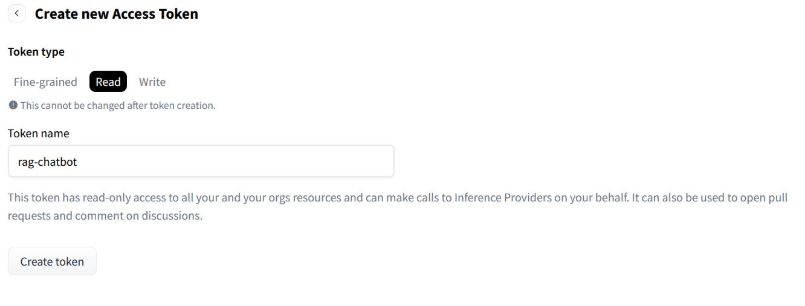
Configurar API Key de HuggingFace
Para este paso necesitamos dar de alta una cuenta de HuggingFace, es totalmente gratuito.
Una vez creada, debemos ir a la sección de tokens para dar de alta uno nuevo, al que asignaremos permisos de lectura. Es muy importante que almacenemos en un lugar seguro la clave generada, ya que no será recuperable después.

Crear chatbot con Streamlit
Este paso ya es conocido, pues utiliza una base parecida a la publicada en el artículo «Crea un chatbot con la API de OpenAI en 40 líneas de código«. En esta ocasión no vamos a emplear la API de OpenAI, sino un modelo Gemma disponible a través de HuggingFace, al que vamos a proporcionarle contexto con RAG.
La idea es que tras mandar nuestra consulta, ocurra el RAG en tres pasos:
- Recuperación del contexto con FAISS (
similarity_search_with_score). - Construcción un prompt estricto con el contexto agregado.
- Llamada al modelo para generar una respuesta.
Al ejecutar el chatbot con el comando streamlit run chatbot.py, se abrirá un navegador donde ya podremos interactuar con el modelo utilizando la base de datos vectorial para ampliar su contexto de conocimiento. En este caso, el rol que va a tener el modelo es para soportar la documentación de Stripe y nada más.
# chatbot.py
import os
import streamlit as st
from langchain_community.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddings, HuggingFaceEndpoint, ChatHuggingFace
from langchain_core.messages import HumanMessage, SystemMessage
FAISS_DB_PATH = "faiss_db"
os.environ["HUGGINGFACEHUB_API_TOKEN"] = "" # Introduce tu token aquí
@st.cache_resource
def load_vectorstore():
# Carga el vectorstore FAISS desde el disco
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True},
)
return FAISS.load_local(
FAISS_DB_PATH,
embeddings,
allow_dangerous_deserialization=True
)
@st.cache_resource
def load_llm():
# Configura el modelo de lenguaje desde HuggingFace Endpoint
llm = HuggingFaceEndpoint(
repo_id="google/gemma-3-27b-it",
task="text-generation",
provider="featherless-ai",
max_new_tokens=512,
temperature=0.2,
repetition_penalty=1.3,
timeout=120,
)
return ChatHuggingFace(llm=llm)
def get_relevant_context(db, query, k=8):
# Recupera los documentos más relevantes para la consulta
docs_with_scores = db.similarity_search_with_score(query, k=k)
context_parts = []
sources = []
for doc, score in docs_with_scores:
source = doc.metadata.get('source', 'unknown')
sources.append(f"{source} (score: {score:.3f})")
context_parts.append(f"[Source: {source}]\n{doc.page_content}")
# Construye el contexto completo
context = "\n\n---\n\n".join(context_parts)
return context
# Inicialización
db = load_vectorstore()
llm = load_llm()
st.title("Chatbot con arquitectura RAG de documentación de la API de Stripe")
if "messages" not in st.session_state:
st.session_state.messages = []
# Mostrar historial
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Input del usuario
if prompt := st.chat_input("Write a message..."):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
with st.spinner("Thinking..."):
# Recupera el contexto relevante
context = get_relevant_context(db, prompt)
# Construye los mensajes para el modelo conversacional
system_prompt = f"""You are a Stripe API documentation assistant. Answer questions using ONLY the documentation provided below.
RULES:
1. Use ONLY information from the DOCUMENTATION section
2. If asked about required fields, look for parameters marked as "required" or without "optional"
3. Be specific and cite the exact parameter names from the documentation
4. If information is not in the documentation, say: "This information is not in my current documentation."
5. Give ONE direct answer. Do NOT generate follow-up questions or continue the conversation.
6. STOP after answering. Do not write anything after your answer.
DOCUMENTATION:
{context}
END OF DOCUMENTATION.
Answer the question directly and then STOP."""
messages = [
SystemMessage(content=system_prompt),
HumanMessage(content=prompt)
]
result = llm.invoke(messages)
response = result.content
st.session_state.messages.append({"role": "assistant", "content": response})
with st.chat_message("assistant"):
st.markdown(response)
No todos los modelos de Hugging Face soportan todas las tareas (por ejemplo <code>text-generation</code> vs <code>chat-completion).
En proyectos reales conviene:
- Elegir un modelo que soporte la tarea que necesitas.
- Fijar un proveedor estable, para este caso Featherless AI.
- Mantener el parámetro
<code>temperature</code>baja para reducir alucinaciones.
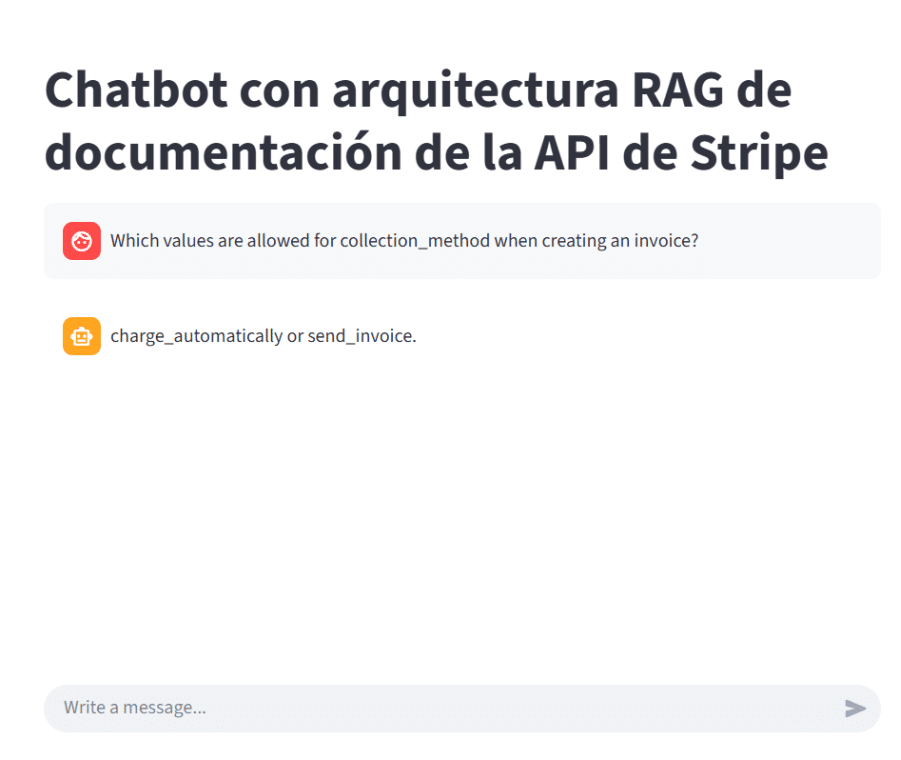
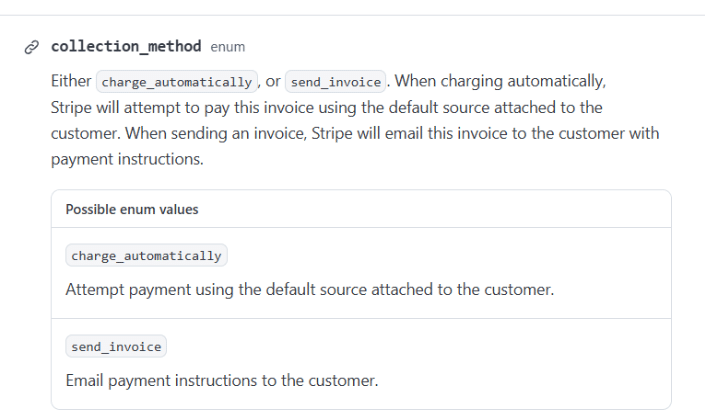
Tras haberle hecho una consulta y recibido su respuesta, podemos cotejar en la propia documentación de Stripe que los valores son correctos para la pregunta realizada.

Conclusiones
De esta forma, en pocos minutos hemos construido un prototipo de arquitectura RAG con LangChain + FAISS + Streamlit que permite potenciar nuestro Chatbot. Tomando como referencia este proyecto, utilizando otros modelos junto a una base de datos vectorial con mayor cantidad y calidad de información sobre un dominio concreto, tenemos a nuestro alcance una poderosa herramienta para facilitar el acceso a la información de forma contextual de dominios específicos.
¿Tienes experiencia o más información relevante sobre la IA? ¡Déjala en nuestras redes sociales! Síguenos en nuestro canal de YouTube para mantenerte al día sobre lo último en el sector digital y tech.