


El término de expresiones regulares nace a partir del término inglés regular expressions. Del que también surgen varias abreviaturas como regex (de REGular EXpressions) o regexp (de REGular EXPressions).
Las expresiones regulares RegEx, no son un lenguaje de programación, sino una serie de símbolos (expresiones o patrones) que nos permitirán definir patrones de búsqueda en cadenas de texto.
Por tanto, las expresiones regulares, no son nada más y nada menos que un lenguaje para manipular/realizar búsquedas sobre archivo de texto o simplemente sobre textos sin la necesidad de que estos estén contenidos en el interior de un fichero.
Qué vas as ver en esta entrada
Historia y origen de las expresiones regulares RegEx
Pitts & McCulloch: creando la neurona de McCulloch – Pitts
El origen de las expresiones regulares se remonta a nada más y nada menos que al 1943 cuando Walter Pitts, un especialista en lógica, realiza una compleja investigación junto a Warren S. McCulloch, un especialista en neurociencia.


Estos dos especialistas, centran su investigación en tratar de entender el funcionamiento del sistema nervioso humano, con el objetivo de crear un modelo que describiera el funcionamiento del sistema nervioso humano. Y por tanto, se trata de buscar cómo el cerebro podría producir unos complejos patrones a partir de células simples.
Un hito importantísimo ya que finalmente, consiguieron crear el primer modelo moderno de Redes Neuronales, siendo este también el más sencillo. Inicialmente, fue conocida bajo el nombre de Threshold Logic Unit (TLU) que traducido al castellano sería algo así como Unidad de Lógica Umbral o Lineal, aunque, suelen ser más conocidas por la comunidad bajo el sobrenombre de “la neurona de McCulloch – Pitts”; haciendo referencia a los dos “padres” de la investigación.


Este modelo de redes neuronales proporcionó una forma de describir las funciones cerebrales en términos abstractos y demostró que los elementos simples conectados en una red neuronal pueden tener un inmenso poder computacional. El cual, intentaba simular el comportamiento que tendría una neurona “natural” en el interior del cerebro humano.
Dicha investigación fué plasmada en la obra: “A Logical Calculus of the ideas Imminent in Nervous Activity,” su traducción sería algo así como
“Un cálculo lógico de las ideas inmanentes en la actividad nerviosa”
Si queréis investigar más sobre el funcionamiento de la neurona de McCulloch – Pitts, os aconsejo visitar el siguiente vídeo: 06. Neurona de McCulloch – Pitts
Finalmente, a modo de curiosidad, y para continuar con la historia de las expresiones regulares, me gustaría destacar, que el origen o los inicios de la creación de las expresiones regulares, no tiene su origen en el campo de la informática, sino en la neurociencia.
Para posteriormente, pasar a ser aplicada en la creación de expresiones regulares dentro del campo de la informática.
Kleene: creando la notación algebraica que representará a las expresiones regulares RegEx
Más tarde, ya en 1951, el matemático Stephen Cole Kleene presenta su trabajo de investigación sobre el asunto publicando un Memorándum llamado “Representation of events in nerve nets and finite automata” en el que, basándose en el trabajo de McCulloch – Pitts añadió una notación algebraica en la que bautizó como “expresiones regulares”.


De hecho, si os fijáis en la primera línea podéis ver que fué encargado por el proyecto RAND de nada más y nada menos que la U.S. AIR FORCE (fuerza aérea estadounidense).


Ken Thompson
Ya durante los años 60, el matemático Ken Thompson, el cual, entre otras muchas cosas destaca por ser uno de los creadores del sistema operativo UNIX. basándose en el legado recibido por las investigaciones de McCulloch – Pitts (la neurona), y principalmente, en el trabajo de Stephen Cole Kleene (la expresiones algebraicas) realiza investigaciones de cómo implementar la idea de las expresiones regulares dentro de un editor de texto conocido como “QED” (cuyo nombre procede de la abreviatura de Quick EDitor).
Este editor inicialmente se escribió con la finalidad de ejecutarse en el sistema operativo Berkeley Time-Sharing System implementado en la Universidad de California entre 1964 y 1967.


Aunque más tarde, ya en 1968, Ken Thompson realizó una reescritura del editor QED para realizar la primera implementación práctica de las expresiones regulares en la informática. Por lo que se produce el importante hito que representa el punto de entrada de las expresiones regulares RegEx dentro de la informática.
Aquí podemos ver un artículo escrito por el mismo Thompson para Bell Telephone Laboratories, en el que detalla aspectos sobre el algoritmo que ha utilizado para implementar las regexp en el editor de texto.
Aunque estas expresiones regulares se han modificado a lo largo del tiempo, y nada tienen que ver las de aquel entonces con las actuales, ya que en parte la sintaxis ha cambiado, tal y como podéis observar en el siguiente memorando escrito para Bells Labs en 1970, algunas de las características de expresiones regulares en QED se siguen manteniendo a día de hoy después de tantos años.
Más nombres legendarios de las expresiones regulares Regex
Posteriormente, la lista de nombres legendarios que han contribuido en la evolución de las expresiones regulares continúa aumentando. Destacando entre ellos algunos nombres como:
 Fuente | Alfred Aho: Coautor de “Dragon Book” en él se habla de cómo realizar compiladores para expresiones regulares. Por si esto fuera poco, además creó la versión inicial del comando de UNIX grep, que tal y como veremos más abajo, permite realizar búsquedas a partir de expresiones regulares sobre ficheros de texto en Unix. |
 Fuente | Jeffrey Friedl: empezó a utilizar expresiones regulares en 1980 y tras muchos años utilizando expresiones regulares en UNIX; finalmente en 1997 publica su primera versión de Mastering Regular Expressions, aquí os dejo el enlace a su tercera edición. |
 Fuente | Jan Goyvaerts: su contribución destaca por su labor en el apartado de la docencia que ha permitido a la comunidad aprender más sobre las regexp mediante a sus contribuciones en RegexBuddy y PowerGREP y las cuales utilizan un motor propio de expresiones regulares conocido como JGsoft. Además de ello, también hay que destacar su contribución a la comunidad al publicar el libro: Regular Expressions Cookbook |
 Fuente | Philip Hazel: su contribución al mundo de las expresiones regulares destaca por realizar una de las mejores bibliotecas de expresiones regulares (la PCRE). La cual es muy utilizada en proyectos como por ejemplo el lenguaje de programación PHP. |
 Fuente | Henry Spencer: destaca por ser el creador de 3 bibliotecas de regex que pueden ser fácilmente utilizadas y/o adaptadas. Además de por lanzar la primera biblioteca regex que permitía ser utilizadas libremente en cualquier programa (en 1986). |
 Fuente | Larry Wall: creador del lenguaje Perl, y que además ha sido un gran precursor de fomentar el uso de expresiones regulares dentro de los lenguajes de programación. Por lo que es uno de los impulsores de que las regex, se hayan extendido a otros lenguajes de programación como Java, .Net, PHP, Python, etc. |




¿Para qué sirven las expresiones regulares RegEx?
Todas ellas, vienen a definir lo mismo, nada más y nada menos que una forma de definir unos patrones que nos permitirán a partir de un conjunto de símbolos encontrar si existen coincidencias, es decir, una determinada combinación de caracteres dentro de una cadena de texto.
Actualmente, son muy utilizadas principalmente para:
Búsquedas en sistemas operativos:
Un ejemplo de uso: Podría ser el utilizar el comando grep en los sistemas basados en UNIX.
GREP es el comando de UNIX que nos permite realizar búsquedas globales
GREP → nace a partir de la combinación de siglas de: G (de Global) + RE (de Regular Expressions) P (de Print).
Por tanto, el significado de GREP nace a partir de las siglas Global Regular Expression Print
Y se podría interpretar como un comando en el que indicamos vamos a realizar una búsqueda Global (en una serie de documentos) en la que haremos un Print (impresión) de todas las líneas coincidentes mediante a una RE (Regular Expression).
GREP destaca por ser un marcar un antes y un después, un gran paso en cómo realizar búsquedas en Unix.
Os animo a realizar esta prueba conmigo desde la web: https://bellard.org/jslinux/ ya que no requiere que tengamos instalado Linux.
Una vez dentro, seleccionamos la opción que hemos marcado en rojo:

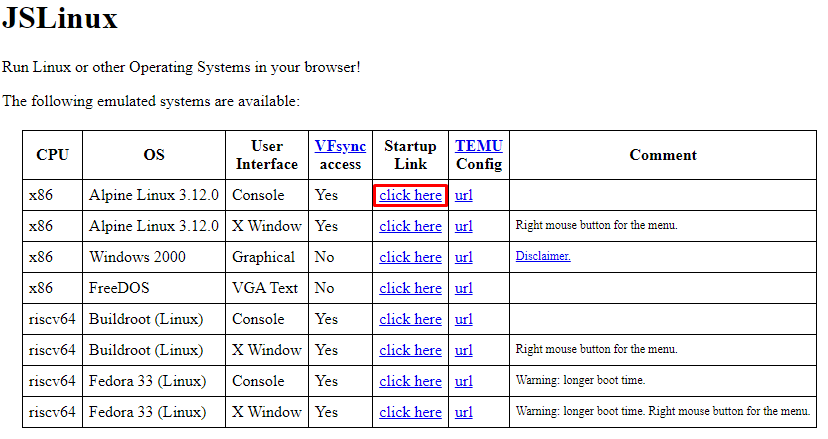
La cual nos abrirá un terminal de Linux dentro del browser:

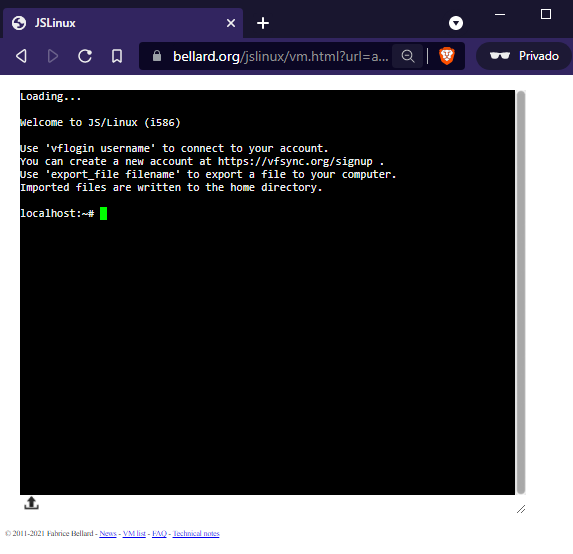
Dentro de este terminal, podremos ejecutar cualquier sentencia que ejecutamos desde un terminal de Linux.
Lo que vamos a hacer primeramente es crear un fichero de texto, en el que añadiremos un texto de ejemplo. Para posteriormente, ver en qué líneas de nuestro fichero aparece nuestro texto buscado. Y finalmente ver varios ejemplos, en los que buscaremos las líneas por ejemplo que tienen la palabra Profile.
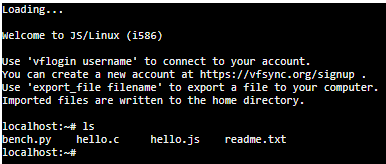
Paso 1) Primeramente, vamos a hacer un ls para listar todos los ficheros actuales:

Paso 2) Continuaremos, creamos un fichero con el siguiente comando y escribimos el texto sobre el que vamos a realizar la búsqueda:

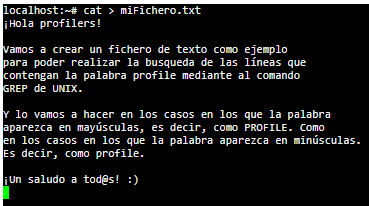
Paso 3) Una vez tenemos el texto escrito, vamos a realizar la combinación de teclas CONTROL + D para poder salir de la edición del texto. Y si nuevamente hacemos un ls nuevamente, podemos ver que tenemos el fichero creado:


Paso 4) Si ejecutamos el comando tail junto al nombre del fichero, podemos ver que el fichero contiene el texto que hemos introducido anteriormente:

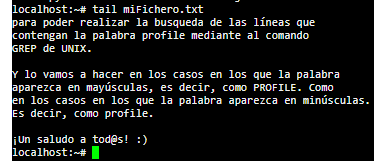
Ejemplo 1) Y ahora, finalmente, vamos a realizar la búsqueda de la expresión regex más sencilla de todas, una palabra sin más. Para ello, tenemos que utilizar el comando grep que requiere de la expresión regular que vamos a buscar, en este caso la palabra profile entrecomillada. Y posteriormente, la ruta junto al nombre del fichero sobre el que vamos a efectuar la búsqueda. Un ejemplo podría ser:

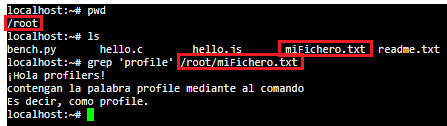
Si nos fijamos solamente, nos devuelve los casos en los que la palabra aparece como minúsculas.
Ejemplo 2) Si repetimos la operación y queremos los casos en los que la palabra aparece como mayúsculas, realizamos lo siguiente:


Ejemplo 3) Si queremos ambos casos, tenemos que añadir el parámetro -i (de insensitive) antes de la palabra a buscar.

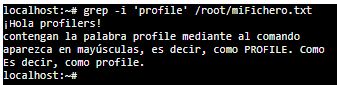
Ejemplo 4) Finalmente, vamos a buscar las líneas que acaben por la palabra profile junto a un punto. Para ello, ejecutaremos el siguiente comando:


Hemos escogido expresiones sencillas ya que es el primer ejemplo. Y aunque grep utiliza expresiones regulares, lo hace de una manera “peculiar/distinta” al resto de expresiones regex que vamos a ver, ya que utiliza parámetros como el que hemos visto con el -i (para coger tanto los elementos que están en mayúsculas como los que están en minúsculas).
Herramientas de procesamiento de texto y/o Entornos de trabajo (IDE’s):
Como pueden ser: Notepad++, Visual Studio Code…
Ejemplo de uso: Vamos a buscar y en algunos casos modificar algunos textos dentro de un fichero de texto.
Para ello, vamos a utilizar el editor de texto Notepad++, y simplemente, creamos un texto:

Vamos a escribir un texto de ejemplo:

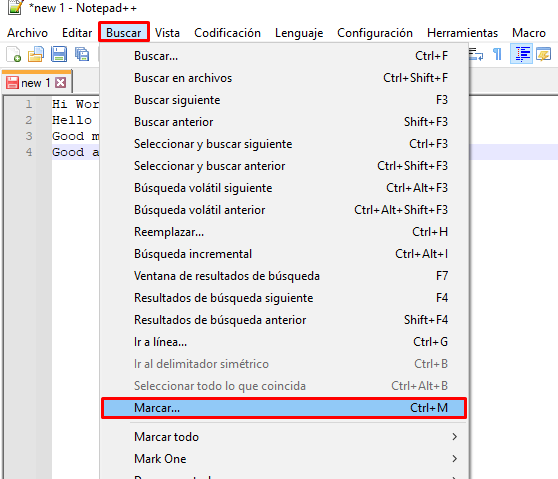
Y para trabajar con expresiones regulares en Notepad++ vamos al menú superior, y pulsamos sobre Buscar>Marcar:

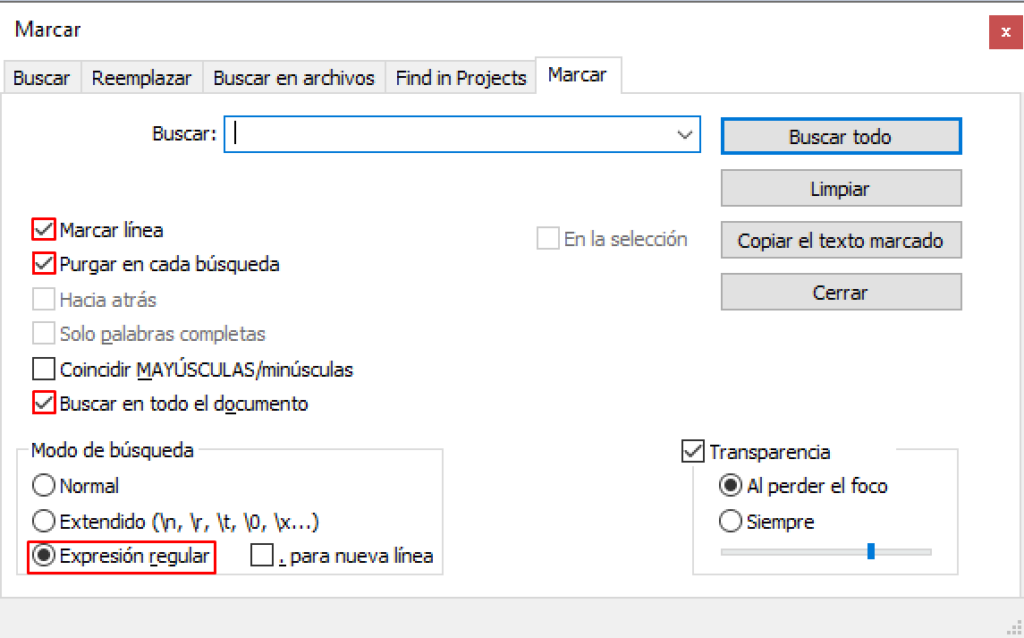
Y finalmente, marcamos los siguientes checks:

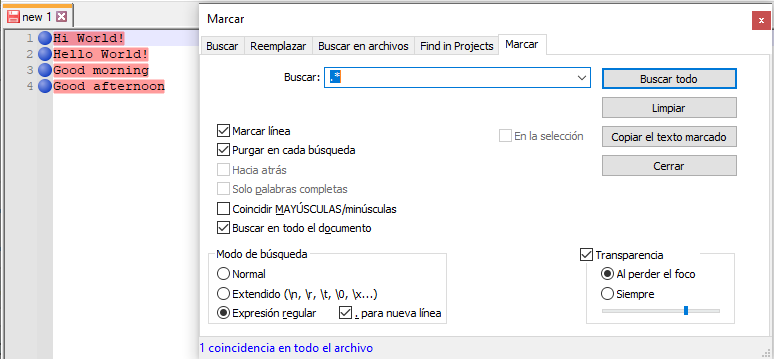
Ejercicio 1) Vamos a seleccionar todo el contenido del fichero. Para ello, vamos a utilizar el metacaracter *, que también es popularmente conocido como estrella de Kleene. Ya que para gran parte de la comunidad, Kleene ha sido el verdadero inventor de las expresiones regulares, y como pequeño homenaje el * lleva su nombre.

Ejercicio 2) Vamos a seleccionar solamente las líneas en las que la primera letra sea una H:

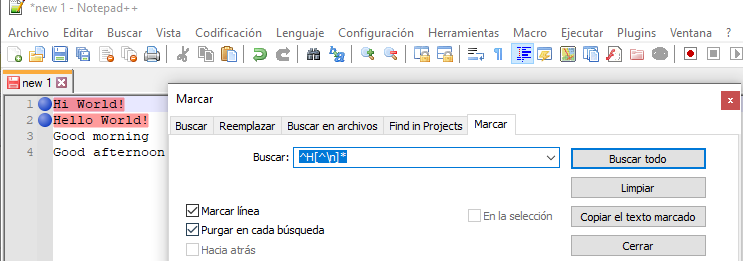
Ejercicio 3) Vamos a añadir la traducción del texto Hello World! mediante expresiones regulares RegEx. Para ello, vamos a realizar lo siguiente:

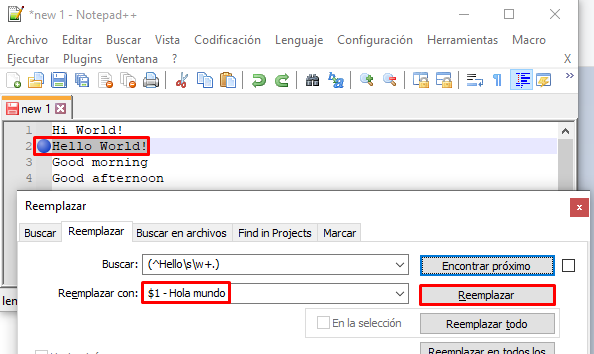
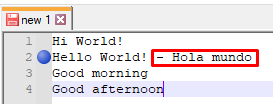
Y tras pulsar reemplazar, podemos ver que se añade correctamente:

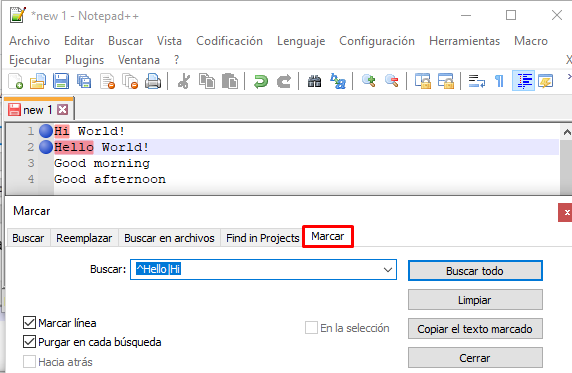
Ejercicio 4) Volviendo al contenido inicial, es decir, sin el – Hola mundo que hemos añadido anteriormente. Vamos a sustituir Hi y Hello por Hola:
Para ello, primeramente, buscamos los casos desde Marcar:

Y posteriormente, vamos a reemplazar, escribimos el texto a reemplazar y pulsamos sobre reemplazar todo:

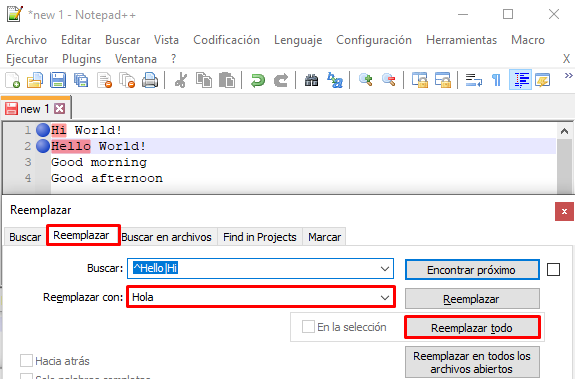
Y vemos que se reemplaza correctamente:

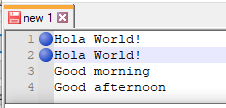
Por lo ya vamos viendo parte de su potencial, podemos sustituir, añadir, modificar el contenido de una serie de frases.
- Lenguajes de programación:
- Como pueden ser: Java, Python, JavaScript…
Ejemplo de uso: realizar validaciones de si un correo electrónico tiene un formato válido o no en Java. Vamos a ver un ejemplo desde el IDE Eclipse:
Primeramente, creamos el proyecto:



Y posteriormente, creamos la clase sobre la que creamos las expresiones


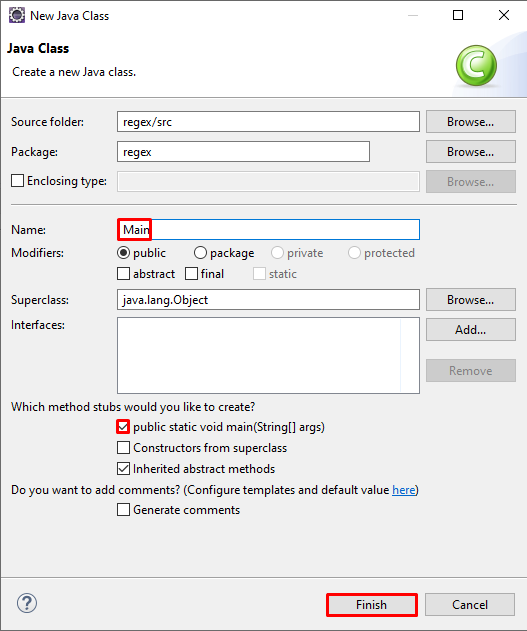
Y solamente tenemos que escribir lo siguiente:
<script src="https://gist.github.com/DavidBernalGonzalez/62e442c2d8ca8707262a864140d043e2.js"></script>
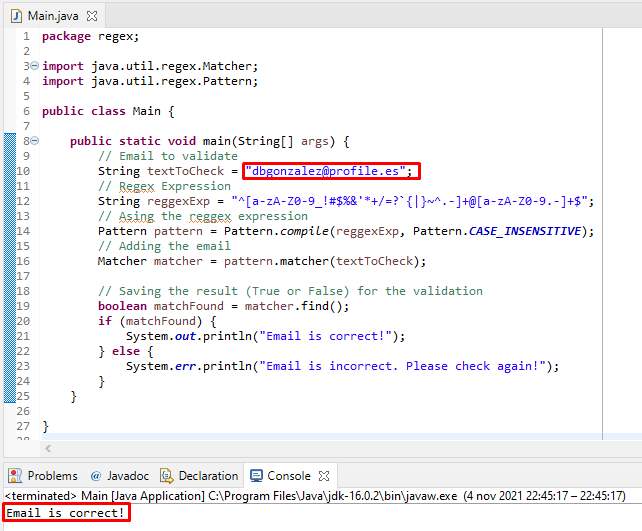
Si ejecutamos el código, en este primer caso, podemos ver que el email ha pasado la validación y por tanto, es correcto.

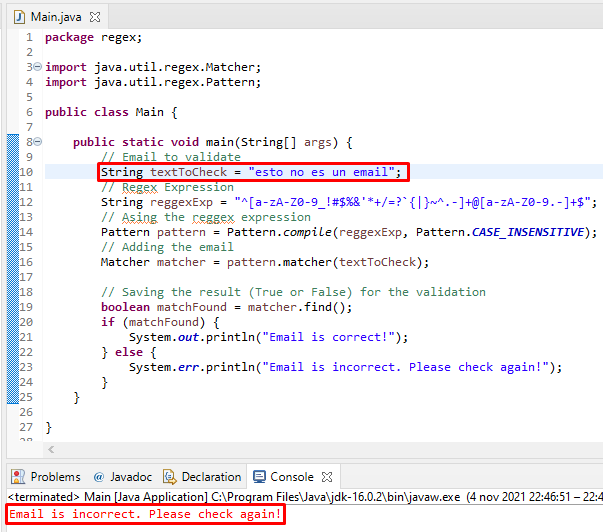
En cambio, si volvemos a ejecutarlo nuevamente con un texto que no tenga un formato de email, podemos ver que nos aparece un mensaje informándonos de que el correo no es correcto:

{kind=link}
{kind=link}
Conclusión
Los avances en la tecnología nunca han sido sencillos y aunque hemos intentado y la historia de los orígenes de las expresiones regulares Regex lo demuestra. En este artículo, hemos intentado viajar al pasado y ver los momentos más célebres de la historia de las expresiones regulares RegEx, además de ver algunos de los beneficios principales de las expresiones regulares acompañados de sus respectivos ejemplos.
Espero que os haya gustado ¡Muchas gracias por la lectura!