


En este post vamos a hablar sobre Spring Batch, en qué consiste, de qué módulos se compone y qué ventajas tiene a la hora de realizar procesamiento batch. Finalmente se incluye un ejemplo de cómo implementar una solución con Spring Batch.
Qué vas as ver en esta entrada
¿Qué es Spring Batch?
Spring Batch es un framework ligero open source para procesamientos batch o procesamientos por lotes. Este framework es un módulo de Spring y fue desarrollado como fruto de una colaboración entre SpringSource (ahora Pivotal) y Accenture.
Dicho framework, además de estar enfocado al procesamiento batch, incluye más herramientas que nos permiten monitorizar estos procesos, disponer de logs, configuraciones, transaccionalidad, estadísticas, alertas, etc.
¿Qué es un proceso batch?
Un proceso batch o proceso por lote es un proceso pensado para trabajar con volúmenes muy grandes de datos y generalmente de una forma programada. Es decir, sin intervención humana.
Imaginemos, por ejemplo, la carga de un fichero enorme con millones de registros; o bien un proceso nocturno que, a partir de una serie de consultas, envía una gran cantidad de e-mails, sms, etc. Esto sería un proceso batch.
Hay que aclarar que Spring Batch no es un planificador de tareas (scheduller), aunque puede incluirse un planificador en el proceso batch. Existen muchos planificadores que pueden integrarse con Spring Batch. Por ejemplo, Quartz y Control-M entre otros.
Componentes de Spring Batch
Este framework está compuesto por los siguientes componentes que vemos en la imagen y que pasaremos a detallar.

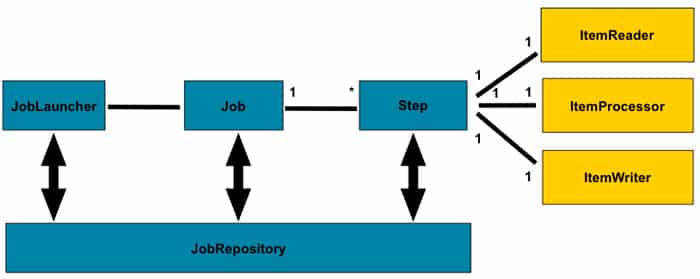
JobRepository
Spring Batch está pensando para que la información de los procesamientos quede almacenada en un repositorio persistente o bien en memoria. Este repositorio se utiliza sobre todo para escritura, aunque también es consultado para comprobar si ya se ha procesado un fichero previamente. También se puede utilizar por si se produce un job fallido, para que en lugar de re-procesar todo el fichero de nuevo, únicamente se re-procese el trozo que ha fallado.
El JobRepository escribe y consulta una serie de tablas existentes en base de datos. Aquí tengo que hacer un inciso y es que la base de datos de este repositorio debe ser transaccional. Como se indica en esta pregunta de StackOverflow, MongoDB no se podría utilizar para el repositorio de Job.
Es responsabilidad de este repositorio almacenar información sobre cada job, step que se produzca, los parámetros del Job, los errores que tengan lugar, etc.
Meta-Data Schema
Una vez se arranca una aplicación Spring Batch, se establece una conexión con la base de datos que contiene el esquema de tablas que utiliza el framework. Si no existe, se puede incluir por configuración que sea el propio framework el que cree el esquema de base de datos. También disponemos de la opción de cambiar el prefijo del nombre que tendrán estas tablas.

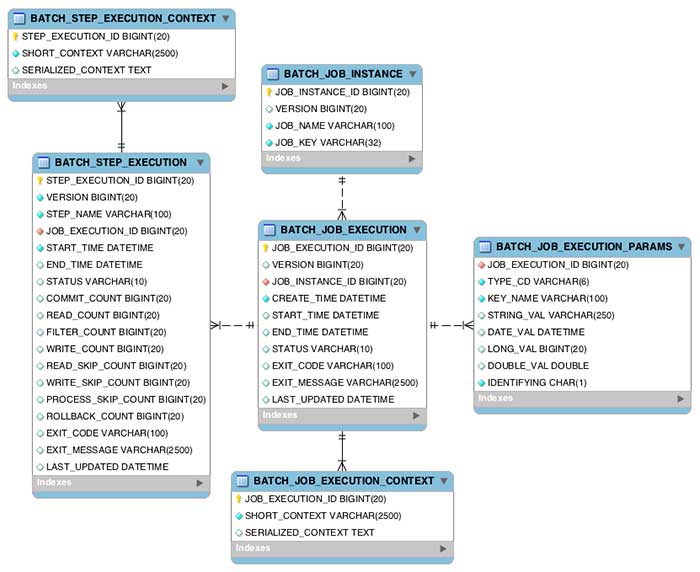
Como vemos en esta imagen, las tablas generadas van enfocadas a los jobs y a los steps. Vamos a proceder a verlas brevemente una a una.
BATCH_JOB_INSTANCE
Esta tabla almacena toda la información referente a las instancias de Job.
BATCH_JOB_EXECUTION_PARAMS
En esta tabla encontraremos los parámetros que recibe cada job en formato clave/valor.
BATCH_JOB_EXECUTION
Se almacena aquí la información referente a cada ejecución del Job. Es muy útil principalmente para conocer el estado de la ejecución, si se ha completado, si ha habido errores, si aún está en ejecución. También, nos sirve para ver la duración del Job por la fecha de inicio y fecha de fin.
BATCH_STEP_EXECUTION
Esta tabla almacena información sobre cada step del job. Es muy similar a la tabla anterior, mostrándonos fecha de inicio y fin de cada step y el STATUS de cada uno de ellos. También nos indica cuántas veces ha leído, escrito y commiteado elementos cada uno de los steps de la ejecución.
Job y Step
Un job es un bloque de trabajo y está compuesto por uno o varios pasos o steps. Una vez se han llevado a cabo todos estos pasos, se considera el job como completado.
Cada uno de estos steps suele constar de tres partes:
- ItemReader: se encarga de la lectura del procesamiento por lotes. Esta lectura puede ser, por ejemplo, de una base datos; o también podría ser de un broker de mensajes o bien un fichero csv, xml, json, etc.
- ItemProccessor: se encarga de transformar items previamente leídos. Esta transformación además de incluir cambios en el formato puede incluir filtrado de datos o lógica de negocio.
- ItemWriter: este elemento es lo opuesto al itemReader. Se encarga de la escritura de los ítems. Esta puede ser inserciones en una base de datos, en un fichero csv, en un broker de mensajes, etc.
Si observamos, está centrado a trabajar con los ítems de manera unitaria. Para el procesamiento por lotes podemos definir de qué tamaño será el número de ítems en el que se organizará el procesamiento por lotes. Si cogemos un tamaño 20, leerá, procesará y escribirá de 20 en 20. Este número de ítems que se procesarán en cada uno de los commits que realice el step se denomina chunk.
Tasklet
Un step no tiene que estar compuesto por un reader, processor y writer. También puede tener únicamente una lógica de negocio. Es el caso del tasklet con el código que se desea ejecutar en el step.
Consejos y buenas prácticas en Spring Batch
A raíz de los tres proyectos en los que he sido partícipe con Spring Batch, hay una serie de lecciones aprendidas que quiero dejar reflejadas para quienes vayan a aplicar esta solución en un proceso y también para mí mismo, a modo de recordatorio. Recalcar que es una visión subjetiva mía propia y que no es una norma. En muchos casos una opinión o preferencia propia basada en mi experiencia.
Principios a la hora de definir un proceso batch
- Simplificar todo lo posible la lógica: de forma que quede fragmentada en procesos muy pequeños de lectura, procesamiento y escritura.
- Utilizar los mínimos recursos posibles: ya que se va a procesar un enorme volumen de datos.
- Revisar y optimizar sentencias sql: es esencial que las consultas estén optimizadas ya que se verá tanto en el redimiendo de la base de datos como en los tiempos de ejecución del job.
- Utilizar comprobaciones checksum: esto es muy útil a la hora de generar ficheros de gran tamaño, incluir en el pie del fichero un contador con el numero de registros e información del procesamiento realizado que puede ayudar a comprobar la integridad del fichero.
- Utilizar pruebas de stress con datos lo más realistas posibles.
Utilizar script para creación del Meta-Data Schema de Spring Batch
En muchas ocasiones no dispondremos de los permisos suficientes para que nuestra aplicación cree en la base de datos las tablas utilizadas por Spring Batch. En muchos proyectos habrá que solicitar en entornos pre-productivos o productivos a un DBA que ejecute un script para la creación de las tablas de Spring Batch.
Por suerte, en la propia librería del framework existen una serie de scripts para distintos sistemas de gestión de base de datos que pueden ser ejecutados tanto para la creación como para la eliminación de las tablas. Pueden localizarse en la siguiente librería.
Recordad deshabilitar en las propiedades el flag que inicializa la base de datos en caso de que no esté creada:
spring.batch.initialize-schema=neverJDBCBatchItemWriter y JDBCBatchItemReader
Por mi experiencia, de cara a optimizar queries y evitar problemas con índices, claves foráneas y otras relaciones que afecten al rendimiento del proceso batch, es muy recomendable que las consultas las configuremos y efectuemos con JdbcBatchItemWriter o JdbcBatchItemReader. No obstante, también podrían efectuarse con Jpa o Hibernate. Pero como digo y por experiencias recientes, puede afectar al rendimiento a la hora de procesar grandes volúmenes de información si alguna configuración a la hora de definir la query no está optimizada.
Aplicación de procesamiento por lotes por separado
Debido a que una aplicación pueda tener desplegadas varias instancias, y por no mezclar la configuración del procesamiento batch con la de otras aplicaciones, es muy recomendable que todo el desarrollo de esta aplicación vaya en un nuevo proyecto/servicio. De esta forma, tendremos el código mas organizado, la lógica mejor repartida y no tendremos el problema de encontrarnos con la aplicación lanzada varias veces y ejecutando el proceso de una manera repetida.
Shedlock
Existen ocasiones en las que esto no es posible. Imaginemos que tenemos que desarrollar un procesamiento batch planificado en un monolito que tiene varias instancias desplegadas. Para estos casos existe una solución llamada Shedlock.
Se trata de un cerrojo por base de datos que permite que un planificador scheduller mediante anotaciones valide que solo ejecute el job en una de las instancias. De esta forma, si tuviéramos, por decir, 3 o 4 instancias intentando arrancar un mismo planificador, la primera bloquearía por base de datos el planificador mientras ejecuta el job y el resto no lo lanzarían.
Ejemplo de Spring Batch
Para finalizar este artículo voy a dejar un enlace a un ejemplo que se ha desarrollado para explicar cómo implementar una solución con Spring Batch. Esta solución se encuentra en un repositorio de GitHub y es posible arrancarla en cualquier equipo que disponga de Docker.
El ejemplo consiste en una aplicación de Spring Boot con Spring Batch que realiza el siguiente proceso batch:
- Lectura de un fichero csv
- Procesamiento del fichero
- Escritura en una base de datos h2
Configuración
En la clase BatchConfiguration.java tenemos toda la configuración del proceso batch. He incluido algunos comentarios.
@Configuration
@EnableBatchProcessing // Es necesario habilitar el procesamiento batch
@RequiredArgsConstructor
public class BatchConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory ;
@Bean //Mediante este bean definimos el reader de csv
public ItemReader<CarDto> reader() {
return new FlatFileItemReaderBuilder<CarDto>()
.name("carItemReader")
.resource(new ClassPathResource("sample-data.csv"))
.linesToSkip(1)
.delimited()
.names(new String[]{"registration", "colour","model","fuelType"})
.fieldSetMapper(new BeanWrapperFieldSetMapper<CarDto>() {{
setTargetType(CarDto.class);
}})
.build();
}@Bean
public CarItemProcessor processor() {
return new CarItemProcessor();
}
@Bean // Mediante este Bean definimos la escritura en base de datos
public ItemWriter<CarEntity> writer(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<CarEntity>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO cars (id, registration, colour, model, fuelType ) VALUES (:id, :registration, " +
":colour, :model, :fuelType)")
.dataSource(dataSource)
.build();
}@Bean // Aquí se define el Job
public Job createEmployeeJob(CarJobExecutionListener listener, Step step1) {
return jobBuilderFactory
.get("createEmployeeJob")
.incrementer(new RunIdIncrementer())
.listener(listener)
.flow(step1) // Se podrían incluir múltiples steps
.end()
.build();
}
@Bean // Aqui se define el step, observamos que se le pasan como parametros reader ,writer y processor
public Step step1(ItemReader<CarDto> reader, ItemWriter<CarEntity> writer,
ItemProcessor<CarDto, CarEntity> processor) {
return stepBuilderFactory
.get("step1")
.<CarDto, CarEntity>chunk(2) // Es posible parameterizar el tamaño del chunk
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}Observamos que hemos incluido en el job un listener. Esto nos permitiría estar a la escucha del comienzo o el fin del job, como vemos a continuación:
@Component
@RequiredArgsConstructor
@Slf4j
public class CarJobExecutionListener implements JobExecutionListener {
@Override
public void beforeJob(JobExecution jobExecution) {
log.info("Executing cars job with id {}", jobExecution.getId());
}
@Override
public void afterJob(JobExecution jobExecution) {
if(jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("Cars job with id {} execution completed", jobExecution.getId());
}
}
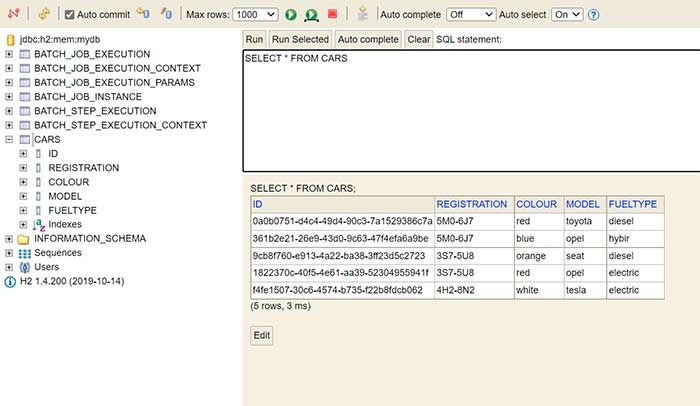
}Finalmente, si deseamos comprobar si la carga se ha efectuado correctamente, si levantamos la aplicación en nuestro local podemos acceder al h2 y observar la carga que se ha realizado, así como las tablas de configuración del proceso batch.
Si accedemos a la base de datos de h2 que se ha creado en memoria al arrancar la aplicación, podemos observar que se ha generado la carga:

Conclusión
En este post hemos hecho una introducción a Spring Batch, analizando de qué módulos se compone y qué ventajas tiene a la hora de realizar procesamiento batch. Además, hemos compartido un ejemplo de cómo implementar una solución con Spring Batch.
Puedes aprender más sobre Spring en nuestro canal de YouTube y en este blog donde hablo también sobre ingeniería de software.