


Introducción
Los Modelos de Lenguaje a Gran Escala (LLMs) como GPT-3 y GPT-4 se han desarrollado y sofisticado a lo largo de la evolución continua de la inteligencia artificial, especialmente en el campo del procesamiento del lenguaje natural (PLN). Estos modelos pueden producir texto humano en una amplia gama de contextos. No obstante, no están exentos de restricciones. Un obstáculo persistente es su tendencia a producir respuestas imprecisas o ilógicas, lo que podría comprometer su utilidad y precisión. RAG (generación aumentada por recuperación), se ha combinado con la búsqueda cognitiva para abordar estas limitaciones.
¿Que es RAG?
La técnica de Generación Mejorada por Recuperación, también conocida como RAG, es una técnica de inteligencia artificial que optimiza la producción de lenguaje natural mediante la integración de información adquirida de fuentes externas.
O dicho de otra manera darle info al modelo previamente a la consulta y solo utilizar sus capacidades de procesamiento para generar la respuesta en vez de usar o a la par con su propio conocimiento.
La técnica mencionada fue inicialmente propuesta por los investigadores de Facebook AI, actualmente conocido como Meta AI, con el fin de abordar las limitaciones intrínsecas de los LLMs. El principal propósito de RAG (generación aumentada por recuperación), es ofrecer respuestas precisas, coherentes y verificables sin la necesidad de altos costos computacionales para la constante reevaluación de los modelos de lenguaje.
¿Qué es fine tuning?
El fine-tuning en el contexto de modelos de lenguaje de gran escala (LLM) consiste en ajustar un modelo preentrenado, como GPT-4, para tareas específicas mediante un entrenamiento adicional con datos específicos del dominio de interés. Esto permite que el modelo mejore su rendimiento y precisión en esas tareas concretas, aprovechando el conocimiento previo adquirido durante su entrenamiento inicial. El fine-tuning es una técnica eficiente que adapta modelos generalistas a necesidades específicas, mejorando su utilidad en aplicaciones particulares sin necesidad de entrenar un modelo desde cero.
Cabe destacar que el fine-tuning es un proceso costoso a nivel económico y computacional, ya que requiere grandes cantidades de datos específicos del dominio y tiempo de entrenamiento adicional. Además, el fine-tuning puede llevar a un fenómeno conocido como «olvido catastrófico», en el que el modelo pierde capacidades generales adquiridas durante el preentrenamiento al enfocarse en tareas específicas.
Cuándo aplicar RAG en lugar de fine tuning
Se debe elegir la técnica adecuada entre RAG y «fine tuning» para maximizar las capacidades de los LLM. A continuación se describen las ventajas de cada método y los casos en los que se recomienda el uso de RAG en lugar del ajuste fino.
RAG vs FINE-TUNING


FINE-TUNING
- Especialización: utilizando datos del dominio, adapta un LLM preentrenado a una tarea específica, tiene especial eficacia en comportamientos en las respuestas.
- Rendimiento dependiente de datos: puede ser costoso porque requiere datos específicos del dominio, es decir, no existe una precisión o cantidad dependiente según la lógica para la que fue entrenado, o dicho de otra manera, ensayo y error.
- Olvido: puede resultar en la pérdida de las capacidades generales que se adquirieron durante el preentrenamiento, es decir, que pierda habilidades que ya tenía.
- Rigidez: cada actualización o cambio en los datos requiere reentrenamiento acompañado de su coste computacional y de tiempo.
RAG
- Conservación de capacidades: mantiene las habilidades generales del LLM dado que no son modificadas.
- Conocimiento externo: mejora la precisión utilizando información recuperada de fuentes externas y más si se utiliza cognitiva con embeddings.
- Flexibilidad: permite cambiar las fuentes de conocimiento sin alterar el LLM subyacente.
- Menor dependencia de datos: no es necesario usar grandes conjuntos de datos específicos del dominio dado que son extraídos de otras fuentes ajenas al modelo llm.
¿Que es la búsqueda cognitiva en términos de IA?

La búsqueda cognitiva es un enfoque avanzado de recuperación de información que imita la manera en que los humanos procesan y comprenden el conocimiento. A diferencia de las búsquedas tradicionales basadas en palabras clave, la búsqueda cognitiva utiliza representaciones semánticas de los datos, conocidos en este caso como embeddings (representación vectorial de tokens), para identificar relaciones y contextos más profundos entre la información.
En el contexto de RAG, los embeddings permiten mejorar la generación de respuestas al proporcionar al modelo información precisa y contextualizada.
Componentes de la búsqueda cognitiva asociado a RAG
Fortaleciendo el RAG mediante el Ensamblaje y el Chunking
La búsqueda cognitiva mejora la eficacia de RAG (generación aumentada por recuperación). Los embeddings, que son representaciones vectoriales de datos que capturan el significado semántico del texto, permiten almacenar y recuperar información de manera precisa y relevante. El proceso de chunking divide la información en partes manejables, facilitando su búsqueda y recuperación.
Generación de Embeddings
Los documentos, políticas y otros tipos de información se transforman en embeddings y se almacenan en una base de datos vectorial. Esto permite una búsqueda rápida y precisa mediante la comparación de estos embeddings medianto los k-nearest neighbors o algoritmos de búsqueda de similitud del coseno.

Identificación de información relevante
Cuando se recibe una consulta, el sistema RAG busca en la base de datos de embeddings utilizando la representación vectorial de la consulta. Algoritmos de búsqueda de vecindad, como la distancia euclidiana o la similitud del coseno, encuentran los fragmentos más cercanos y pertinentes.
Selección y uso de información pertinente
Los fragmentos más relevantes se recuperan e integran con la consulta inicial del usuario, garantizando que la información proporcionada al LLM sea la más precisa y adecuada para generar una respuesta coherente y contextualizada.
Comparación de aplicaciones: RAG en comparación con el ajuste fino
Modelos grandes
RAG es mejor para modelos masivos como GPT-4:
- Mantiene Capacidades Previas: mantiene las habilidades generales en mente.
- Utiliza Conocimiento Externo: incorpora información actualizada y específica sin tener que volver a aprender.
- Evita el Olvido Catastrófico: mantiene la versatilidad del modelo.
- Flexibilidad de las fuentes de conocimiento: facilita la actualización de bases de datos sin la necesidad de realizar un reentrenamiento.
Modelos Medianos
Ambos métodos son factibles:
- FINE TUNING: ideal para tareas que requieren memorización intensiva.
- RAG: útil para tareas que requieren la generación o clasificación de datos específicos.
Modelos más pequeños
El fine-tuning generalmente es más apropiado:
- Capacidades limitadas: carecen de una amplia gama de habilidades generales.
- Enfoque directo: transmitir de manera efectiva el conocimiento específico de la lógica de intención.
- Menor riesgo de olvido: se requiere poco entrenamiento y se puede actualizar fácilmente.
Aplicaciones prácticas de RAG (generación aumentada por recuperación)
- Gestión y Asesoramiento de Inversiones: RAG es ideal para recuperar datos de perfiles de clientes y datos de mercado, ofreciendo asesoramiento financiero personalizado sin comprometer las capacidades de conversación.
- Chatbots de atención al cliente: un enfoque híbrido que combina RAG para charlas generales y ajuste fino para el conocimiento de la empresa puede equilibrar capacidades conversacionales amplias con conocimiento específico.
- Chatbot de documentos informativos: RAG puede acceder a información sobre políticas e información específica y dar respuestas precisas a los usuarios.
- Campo de la Salud: RAG puede ayudar a los profesionales médicos a identificar casos clínicos similares y enriquecer su conocimiento con datos de investigaciones recientes en una etapa preliminar de diagnóstico.
- Ámbito Educativo: utilizando libros de texto y artículos académicos, los asistentes virtuales basados en RAG pueden ofrecer respuestas precisas y contextualizadas a las preguntas de los estudiantes.
Desafíos y perspectivas técnicas para el futuro
La implementación de sistemas RAG presenta desafíos técnicos, como la necesidad de algoritmos de búsqueda complejos y bases de datos estructuradas. La coherencia y la fluidez del texto generado deben mantenerse integrando la información recuperada.
Otras técnicas iterativas e interactivas
Además de RAG, existen otras estrategias que no se centran en enriquecer la entrada, las cuales también tienen el potencial de aumentar la eficacia de los sistemas de inteligencia artificial. Las técnicas menos reconocidas, como el «self-ask», involucran la repetición y la interacción con la respuesta generada por uno mismo, lo cual puede incrementar la calidad y pertinencia de las respuestas producidas.
A continuación se presentan algunos ejemplos:

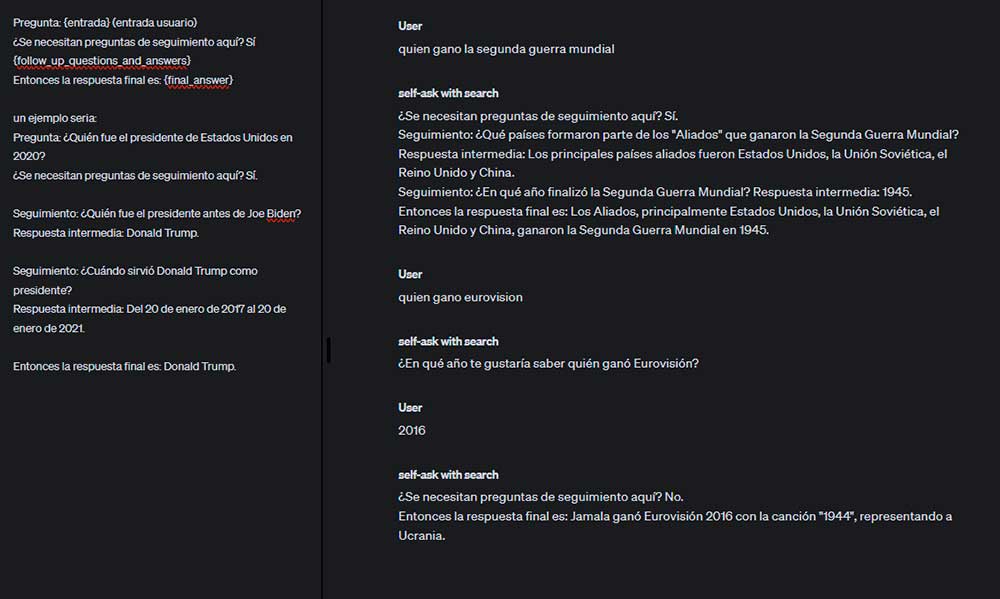
En este asistente se emplea una técnica conocida como «self-ask», la cual consiste en formular una respuesta en forma de pregunta con el fin de permitir al usuario interactuar con el asistente y explorar más a fondo el tema. La técnica mencionada promueve la interacción del usuario y optimiza su experiencia de aprendizaje.

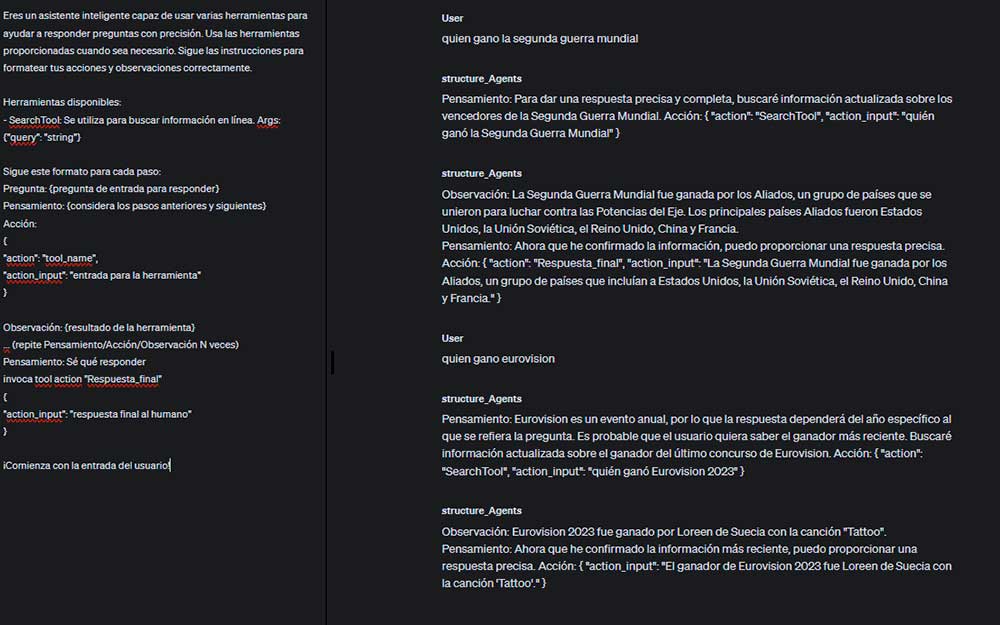
En este asistente, también se emplea la técnica de «auto-pregunta», la cual se utiliza para ofrecer información adicional y contextualizada utilizando RAG según sea necesario.
Conclusión
La Generación Mejorada por Recuperación (RAG) es un gran avance en el procesamiento del lenguaje natural. RAG mejora la precisión, relevancia y actualización de las respuestas de los LLM al combinar la recuperación de información con la generación de contenido y la búsqueda cognitiva mediante chunking y embedding. Esta estrategia podría transformar una variedad de aplicaciones, incluidos chatbots comerciales y asistentes virtuales para la educación y la salud. Es probable que los sistemas RAG tengan un papel cada vez más importante en la mejora de la interacción humano-máquina y en la inteligencia artificial generativa a medida que se desarrollan y mejoran. Al comprender cuándo y cómo usar RAG, las organizaciones pueden maximizar el rendimiento y la utilidad de sus modelos de lenguaje.
¿Quieres aprender más sobre Inteligencia Artificial y las últimas novedades en tecnología? Síguenos en nuestras redes sociales y canal de YouTube.