

En este post te contamos qué es Pandas, por qué utilizarla y cuáles son las principales características de esta librería de Python.
Qué vas as ver en esta entrada
¿Qué es Pandas?
Pandas es una muy popular librería de código abierto dentro de los desarrolladores de Python, y sobre todo dentro del ámbito de Data Science y Machine Learning, ya que ofrece unas estructuras muy poderosas y flexibles que facilitan la manipulación y tratamiento de datos.
Pandas surgió como necesidad de aunar en una única librería todo lo necesario para que un analista de datos pudiese tener en una misma herramienta todas las funcionalidades que necesitaba en su día a día, como son: cargar datos, modelar, analizar, manipular y prepararlos.
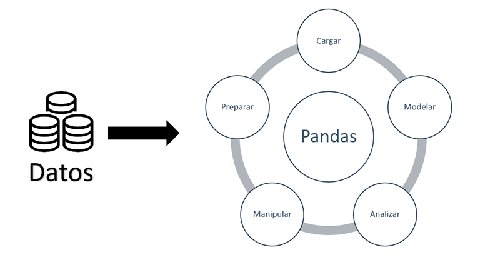

Estructuras de datos en Pandas
Las dos estructuras de datos principales dentro del paquete Pandas son:
- Series: array unidimensional etiquetado capaz de almacenar cualquier tipo de dato.
- DataFrame: estructura bidimensional con columnas que pueden ser también de cualquier tipo. Estas columnas son a su vez Series.


Dado que vivimos en un mundo en el que los datos son de muy distintas categorías, Pandas se realizó con el objetivo de poder tratar con el mayor número posible de casuísticas entre tipos de datos. Es muy simple cargar datos desde diferentes tipos de archivos (csv, json, html, etc.), así como guardarlos.
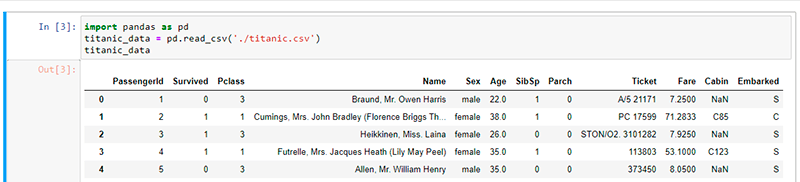
A continuación, se mostrará un ejemplo de cómo cargar datos desde un .csv con una sola línea:

Analizar datos con Pandas
A día de hoy, aunque no seamos todavía del todo conscientes, vivimos en un mundo en el que podemos sacar información muy valiosa de los datos, aunque a priori no la conozcamos. El principal problema que nos encontramos es que, a simple vista, no somos capaces de obtener ese conocimiento, por eso necesitamos de herramientas como Pandas que nos ayuden en este proceso.
A continuación se enumeran funciones muy valiosas de Pandas que pueden ayudarnos para hacer un análisis en profundidad de los datos con los que se esté trabajando:
- head(n): Esta función devuelve las primeras n filas de nuestro DataFrame.


- tail(n): Devuelve las n últimas filas de nuestro DataFrame.

- describe(): Esta función da estadísticas descriptivas incluyendo aquellas que resumen la tendencia central, dispersión y la forma de la distribución de los datos.


Filtrado y manipulación de datos con Pandas
Hasta ahora el artículo se ha centrado en algunos resúmenes e información básica del conjunto de datos que estamos usando como ejemplo, sin tener en cuenta la estructura de datos que tenemos. Pandas nos permite obtener columnas o filas de nuestros datos de forma muy fácil e intuitiva. Además, podemos hacer una exploración basándonos en condiciones tal como veremos a continuación.
Seleccionar columnas o filas específicas
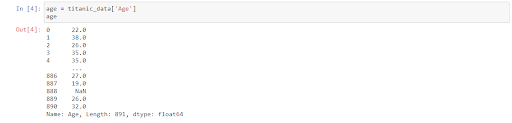
¿Qué pasa si sólo estamos interesados en una columna de nuestro conjunto de datos? Con Pandas podemos usar los corchetes “[]” para extraer cualquier columna.

En el caso de querer extraer solamente una fila tenemos dos opciones:
- .loc: para extraer por nombre de fila
- .iloc: para extraer por el índice numérico
Para extraer por ejemplo la fila cuyo índice es 0, se haría con la siguiente instrucción:


Selecciones condicionales
Con Pandas también podemos hacer selecciones condicionales como, por ejemplo, cuáles son las filas que tienen una edad mayor a 45. Para este tipo de cuestiones es necesario tomar una columna de nuestro DataFrame y aplicarle una condición booleana.
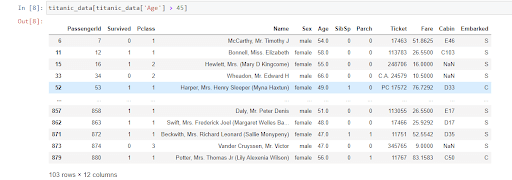

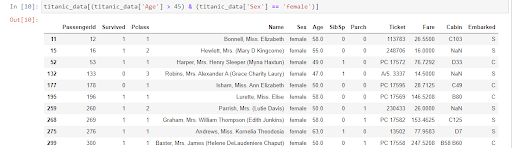
También se pueden realizar tratamientos más sofisticados combinando varios operadores booleanos. Por ejemplo, para saber qué pasajeros tienen una edad mayor de 45 años y son mujeres deberíamos utilizar la siguiente línea de código:

Gráficos en Pandas
Otra de las ventajas de Pandas es que viene integrado con Matplotlib, una librería muy conocida para hacer gráficas. Por lo que se puede realizar de forma muy cómoda y sencilla cualquier gráfico directamente a partir de un DataFrame o Series.
La función que se usa para realizar gráficos es plot(). Esta función cuenta con un parámetro de entrada, “kind”, que sirve para especificar el tipo de gráfico que se desea obtener a partir de un DataFrame o Series. A continuación se enumeran las opciones disponibles para este parámetro:
- area: gráficos de áreas
- bar: diagramas de barras verticales
- barh: diagramas de barras horizontales
- box: diagrama de cajas y bigotes
- hexbin: para diagramas hexagonales
- hist: histograma
- kde: gráficos de estimación kernel de la densidad
- density: alias para “kde”
- line: gráficos de líneas
- pie: diagrama de tartas
- scatter: diagrama de dispersión
Por ejemplo, para visualizar un histograma con la distribución de la variable “Age”, deberíamos usar la función plot y el parámetro “kind” con valor “hist”:
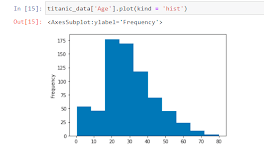

Además del tipo de gráfico que queremos obtener, se pueden modificar muchos detalles de estilo, como los colores, los nombres de los ejes, el tamaño, etc.
Conclusiones
La gran cantidad de datos que estamos generando continuamente hace necesario tener herramientas potentes que permitan sacar el máximo provecho de ellos. Pandas es una librería de código abierto que surgió para hacer más fácil todo el ciclo de vida de cualquier dato, desde que este es generado hasta que es aprovechado.
Permite, de forma fácil e intuitiva realizar operaciones capaces de gestionar y manipular cualquier tipo de información sin importar el formato, y sobre todo de una forma rápida y eficaz. Esto hace que Pandas se haya convertido en el mejor amigo de cualquier curioso por los datos.
¿Has utilizado alguna vez Pandas? ¿Usas otra librería para trabajar con datos? ¡Comparte tu experiencia! Si no quieres perderte más contenidos como éste, ¡suscríbete a nuestro canal de YouTube!