
Una red neuronal es un modelo de procesamiento basado en el aprendizaje que se inspira en el funcionamiento del sistema nervioso de los animales. Pese al fundamento biólogico del modelo, para nosotros los desarrolladores, el uso de una red neuronal viene a resumirse en la llamada a unos pocos métodos de una API. ¿Qué ocurre entre bastidores para emular ese aprendizaje?
1. De estimador de precios a red neuronal
Supongamos que queremos construir un estimador de precios de inmuebles en función de varios parámetros: área, número de habitaciones, distancia a la capital más cercana, piso, antigüedad, y piso o altura. Lo que buscamos es una fórmula de este estilo:
Precio = P1 * area + P2 * habitaciones + P3 * distancia a capital + P4 * antigüedad + P5 * piso
Cada peso estará expresado en la unidad correspondiente (P1 en euros/m2, P2 en euros/habitación, P3 euros/km, etc.); ahora sólo nos importa su valor. Para determinarlo preguntamos a varios expertos tasadores. El primero, que por ejemplo, trabaja sobre todo con locales comerciales, considera una estimación adecuada la que se obtiene a partir del área y de la distancia a la capital:
Precio = P1 * area + P3 * distancia a capital
En la estimación sólo nos importan dos cosas: el valor de los parámetros y el de los pesos. La operación siempre va a ser una suma ponderada. Vamos entonces a representar cada suma ponderada mediante un nodo Ei, y su inclusión en la suma mediante una flecha. La primera fórmula de estimación quedaría así:
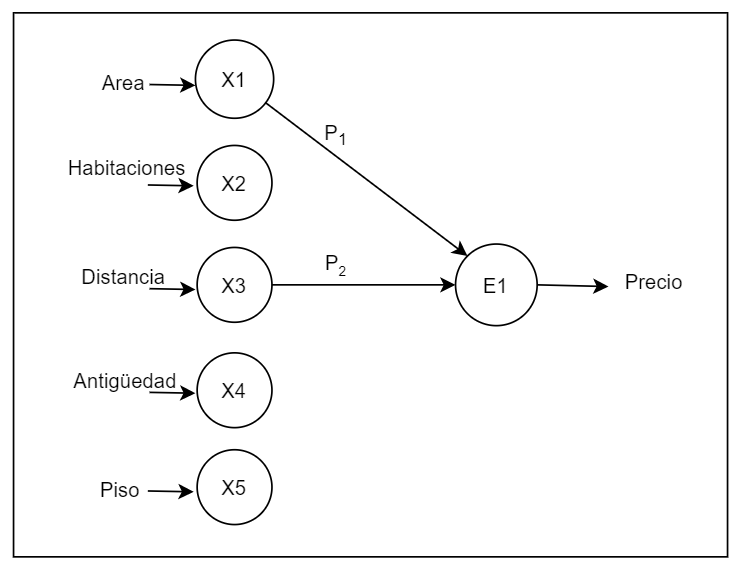
Otro tasador, por su parte, acostumbrado a trabajar el ámbito de las viviendas familiares, prefiere estimar basándose en el número de habitaciones y la distancia a la ciudad:
Precio = P2 * habitaciones + P3 * distancia a capital

Otra tasadora, experta en segundas residencias, tiene en cuenta el área, el número de habitaciones y la antigüedad:
Precio = P1 * area + P2 * habitaciones + P4 * antigüedad

Por último, hay quien considera más relevante el área, la distancia y el piso, habituado a tasar inmuebles para oficinas:
Precio = P1 * area + P3 * distancia a capital + P5 * piso

¿Qué fórmula elegimos para construir nuestro estimador de inmuebles? Cada una utiliza un conjunto de parámetros distintos y los pondera de acuerdo a criterios diferentes. Si las reunimos resultará algo como esto:

¿Y si intentamos combinar las diferentes estimaciones, ponderándolas a su vez?:

Ahora bien, podemos interpretar la ausencia de conexión entre dos nodos como un peso con valor cero. Si representamos las posibles combinaciones independientemente del valor asignado, tendremos:

Esto ya va mereciendo el sonoro nombre de red neuronal. La primera capa de los Xi es la capa de entrada. La segunda de los Ei, la capa oculta o interna; de este tipo podríamos tener varias. La última capa, con un solo nodo (o neurona) en nuestro caso, es la de salida.
2. Aprendizaje
Pero, ¿qué valores asignamos a los pesos con que cada Ei contribuye al E final? ¿Con respecto a qué criterios? Supongamos que, en vez de opiniones de expertos, tomamos como referencia un histórico de precios en función de los parámetros Xi.

Pues bien. Al algoritmo por el cual se asignan valores a los pesos de nuestra red a partir de esos datos se le llama aprendizaje automático.
Este aprendizaje consta de dos fases: la propagacióny la retropropagación. Al principio, los pesos están inicializados aleatoriamente. De la tabla de datos, reservaremos un porcentaje para la validación del aprendizaje. Mediante la repetición de estas dos fases de propagación y retropropagación los valores iniciales de los pesos van a ir corrigiéndose (“convergiendo”) de modo que la red replique la tabla de datos. Es decir, al terminar el aprendizaje, cualquier entrada de nuestra tabla dará como resultado el precio en euros previsto, porque la hemos entrenado con ella. Si estos datos de inicio son lo suficientemente numerosos, podemos esperar que una entrada de datos distinta de las de la tabla arroje como resultado en nuestra red una estimación razonable. Es decir, para nuevos datos respecto de los usados para el aprendizaje, la red ofrece una estimación de precio bastante probable. Para comprobarlo, usamos las entradas que habíamos reservado para validación, y obtendremos una medida de error para nuestra red. Pero aunque este error sea mínimo, hay que tener presente que una red neuronal nunca va a ser mejor que los datos con la que se la entrena. Si los datos están sesgados, las predicciones de la red también lo estarán. Es decir, la red neuronal es reproductiva respecto al pasado.
A. Propagación
En la primera fase, la de propagación, el algoritmo alimenta la red con una entrada concreta y calcula la estimación de precio. El proceso comienza con la primera fila de la tabla:

Y se van realizando los cálculos en cada neurona, de acuerdo a las fórmulas de los Ei que vimos arriba:

El valor resultante es, por ejemplo, 345.778 (al ser los pesos iniciales aleatorios, puede ser un resultado cualquiera), mientras que el deseado, según nuestra tabla, es 168.767.
B. Retropropagación
En la fase de retropropagación el algoritmo va a corregir los pesos para ajustar la entrada al valor deseado que indica la tabla. A partir de la diferencia entre el valor obtenido y el deseado se calcula una medida de desviación C, que el algoritmo usa para ajustar cada uno de los pesos de la red, aumentándolo o disminuyéndolo en cada caso. Por eso es esencial que los pesos se inicialicen aleatoriamente: si al comienzo tuvieran el mismo valor, la corrección sería la misma en todos los pesos y no podría haber aprendizaje alguno.
Vemos también la importancia de la capa oculta: en cierto modo, desacopla la salida de la entrada. A mayor número de capas ocultas, menor «reactividad», por así decir, de la salida. Una segunda capa oculta en nuestra red serviría para combinar las estimaciones parciales E1, E2, E3 y E4 en estimaciones parciales de orden superior.

Una vez completado el ciclo propagación-retropropagación, se repite para la siguiente entrada de nuestra tabla de datos:

De nuevo el algoritmo obtiene una estimación del precio, lo compara con respecto al precio deseado, calcula la medida de desviación C, y modifica cada peso teniendo en cuenta esta medida C. Y sucesivamente, el ciclo se repite con todas las entradas de nuestra tabla (excepto con las que hemos reservado para la validación).
Este proceso completo, a su vez, puede repetirse varias veces, cada una de las cuales recibe el nombre de época. Determinar el número de épocas adecuado para una red, así como el valor de ciertos parámetros (como el factor de velocidad en la asignación de pesos, o el número de capas ocultas) dependerá de la intuición y experiencia que tengamos como entrenadores de redes neuronales…
Como ocurría cuando pedíamos la opinión a varios expertos, también ahora podemos entender cada neurona como una perspectiva en la estimación del precio de un inmueble. Solo que el sentido de esta perspectiva no está predefinido: viene dado por el proceso de aprendizaje. Hay que notar que, debido a que la asignación inicial de pesos es aleatoria, cada ejecución del proceso de aprendizaje dará un resultado distinto: una determinada neurona terminará aprendiendo de distinta manera, es decir, acabará con una serie de pesos diferente.
Para más adelante…
Nuestro ejemplo no pretende ser más que una introducción al concepto de red neuronal; el tema es amplísimo ya sólo en el nivel básico. Para empezar, esta forma de aprender de nuestra red neuronal no es la única posible. Nuestro caso es un ejemplo de aprendizaje supervisado, porque se hace con respecto a unos valores de precios determinados que nosotros proveemos mediante una tabla. Pero también es posible el aprendizaje no supervisado, en el que la red neuronal encuentra por sí misma regularidades en los datos (p.e., los clasificadores).
Además, los nodos E en realidad constan de una función de agregación y otra de activación, que depende de la anterior. En nuestro caso, la función de activación simplemente devolvía el resultado de la de agregación (la fórmula de estimación de precio). Pero existen muchas variantes de función de activación (lineal, en escalón, sigmoidal, gaussiana…) que merecen una explicación aparte.
No hemos mencionado tampoco el farragoso asunto de la preparación y normalización de los datos, ni tenemos espacio para revisar las bibliotecas (como p.e. TensorFlow Keras) que implementan estos algoritmos de aprendizaje por nosotros y nos permiten construir una red neuronal en pocas líneas de código…
Queden estas cuestiones pendientes para otras entradas del blog.


