
No se me ocurre mejor manera de introducirnos en por qué nacen los nuevos y tan populares términos como Big Data, Data Science, Machine Learning o Artificial Intelligence y que tantas nuevas profesiones en el mundo IT, que hacer un viaje al pasado. Este nos permitirá remontarnos a cuando los ordenadores ocupaban habitaciones al completo y sus discos duros también. En este post hacemos un repaso por la historia, desde la creación del primer disco duro Ramac I, hasta la llegada de la Inteligencia artificial.

Qué vas as ver en esta entrada
IBM distribuye el primer disco duro Ramac I
Me gustaría que hagáis el ejercicio mental de viajar en el tiempo a un momento histórico en el mundo de la informática como si de la película “Regreso al futuro” se tratara y os situéis en 1956. En aquel año, en que IBM, decide empezar a distribuir el primer disco duro para uso comercial; el conocido como Ramac I que introdujo en sus supercomputadoras IBM350.

Las cifras del Ramac I son escalofriantes, un tamaño similar al de un frigorífico de doble puerta, un peso muy superior al de una tonelada y con una capacidad de solamente 5 MB.

RAMAC proviene de Random Access Method of Accounting and Control, y su traducción podría ser algo así como «sistema de almacenamiento y control por acceso aleatorio»
Os suelto toda esta retahíla de momentos históricos para que podáis entender la evolución viendo con vuestros propios ojos cómo han evolucionado los dispositivos almacenamiento de datos.
Una muestra de ello, son las dificultades a las que se enfrentaban para introducir el primer disco Ramac I en el interior de un avión a través de la compuerta. Ahora quiero que lo comparéis con el peso o el esfuerzo que os puede suponer, el llevar o el introducirnos un pendrive en uno de vuestros bolsillos.

Problemas del Ramac I y de sus predecesores
Un factor determinante para incrementar la capacidad de los dispositivos de almacenamiento, como ya hemos visto con el ejemplo del pendrive, ha sido la reducción del tamaño ¡Imaginaos cómo hacer un GB con unidades Ramac I que tenían tan solo 5 MB de almacenamiento!
Como ya estaréis pensando, necesitaríamos muchas unidades además de un gran espacio físico para situarlas, por no hablar de su elevado coste. Un ejemplo de ello, es que el precio del IBM350 en 1957 como leasing (una especie de alquiler) costaba 3.200$ sin contar la infracción. Y nada que ver con lo que nos cuesta hoy en día un pendrive estando este último a años luz en varios aspectos como su precio, su tamaño, su rendimiento, etc.
La ley Moore
Todo ello, ha sido posible gracias a la evolución y aquí es donde entra en juego la famosa y popular teoría conocida como la “Ley de Moore”, en la que el cofundador de Intel, Gordon Moore, predijo tras una observación que la densidad de transistores, y por tanto, también de rendimiento, de los microprocesadores se duplicaría cada 18 meses.
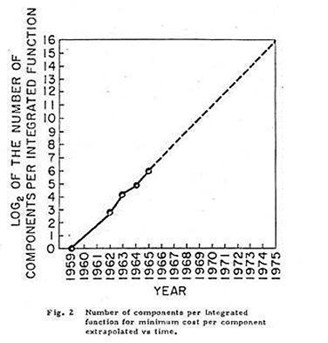
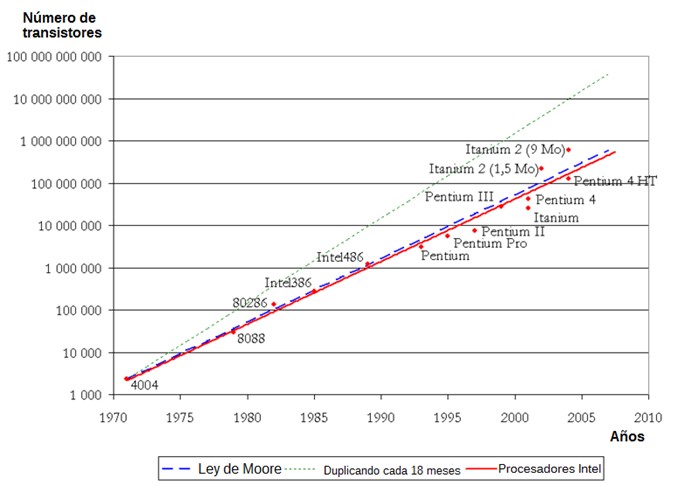
Reduciendo los problemas
La propia evolución de los dispositivos en el ámbito de la informática ha ido reduciendo los problemas a los que nos enfrentamos en el pasado hasta llegar al punto en el que el tamaño de almacenamiento ya no suele ser un problema y muestra de ello es que en un uso doméstico es habitual que las unidades trabajen con medidas como GB, o TB.
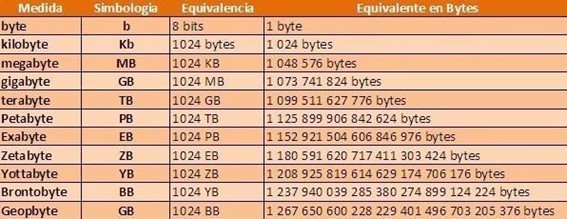
¿Qué hacemos con tanto volumen de datos?
Si combinamos un aumento de las capacidades tanto de almacenamiento acompañadas por una mejora de rendimiento de los dispositivos, resulta una reducción del tamaño y del precio. Llegamos al escenario perfecto para que las empresas busquen almacenar cada vez más y más datos de sus empresas como, por ejemplo, un me gusta en una red social, cada cookie de una visita a una página web, cada búsqueda realizada en un buscador, cada visualización de un video de YouTube, etc.
Provocando la atmósfera perfecta para que se consideren a los datos bajo el término de “oro líquido” y fomentando la aparición de un mundo de nuevas profesiones relacionadas con el Big Data, Data Science, Machine Learning, Deep Learning, etc.; como son Big Data Engineer, Data Scientist, Machine Learning Engineer, Machine Learning Engineer o Business Intelligence (BI) Developer, etc.
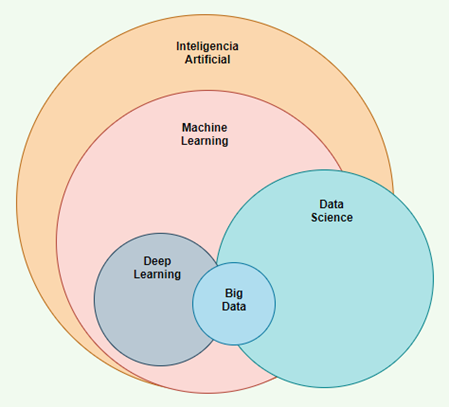
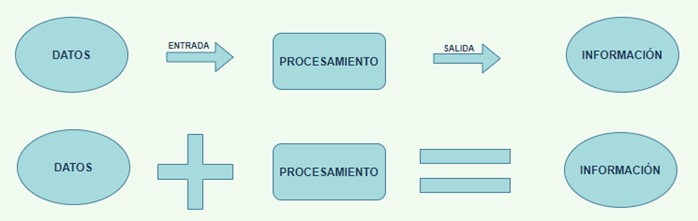
¿Cuáles son las principales diferencias entre datos e información?
Hasta ahora hemos tratado de algunas características de unidades de almacenamiento, pero no hemos hablado de las diferencias entre datos e información.
Si os digo tengo número 3 sin contexto alguno, es decir, sin saber que es estamos hablando, se trata de un dato, ya que aún no hemos sido capaces de realizar el procesamiento del dato de entrada y lo normal es que vosotros me preguntarais ¿3 que? A lo que yo os contestaría 3 peras o 3 kg de peras y una vez sí que somos capaces de procesar/interpretar dicho dato, nos encontramos ante información.
Un dato, por tanto, es algo que no está procesado. Cuando somos capaces de procesar dicha información, estamos hablando de información. El ordenador trabaja con datos y nosotros como seres humanos interpretamos/procesamos dichos datos, pasando en ese preciso momento (una vez interpretados) a conocerse bajo el término de información.
Conclusión
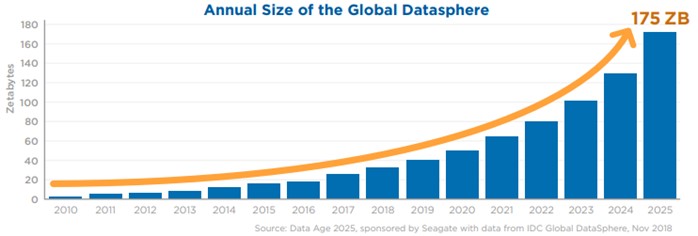
Para finalizar, os comparto los datos de un estudio realizado por Seagate, un importante fabricante de discos duros, en el que se informa que el volumen de datos anual mundial pronosticado para 2025 será 175 zettabytes, lo que se traduce en 175 veces la información generada en 2011.
Y todo este inmenso aumento del volumen de datos, propicia que servicios de computación en la nube como el que nos ofrece Microsoft mediante Azure, estén constantemente creando nuevos Data Centers en muchas partes del mundo.

Os animo a realizar un tour sobre un Data Center de Azure desde siguiente enlace.
¿Qué te ha parecido el post? ¿Conocías la historia del Ramac I? ¡Cuéntanos en redes sociales!


