
¿Cuántas veces hemos tenido que incorporarnos a un proyecto existente del cual no conocemos ni siquiera su modelo de datos ni está documentado de ninguna manera? ¿Cuántas veces hemos tenido que integrar contra bases de datos de las cuales desconocemos sus tablas y cómo se relacionan entre ellas?
Seguro que todos nosotros nos hemos encontrado alguna vez con alguna de estas situaciones, donde la única solución que tenemos es preguntar a quién lleve mucho tiempo con el proyecto (dependiendo de la disponibilidad de ésta persona), mirar una a una las tablas e intentar descifrar el modelo o, si tenemos mucha suerte, existirá algún documento de cuando la base de datos se creó, el cual seguramente esté desactualizado.
Siendo el modelo una pieza tan importante de nuestro sistema (por no decir casi la que más), debería ser la primera por la que empezáramos a documentar, puesto que un modelo bien documentado te permitirá entender la lógica funcional de tu sistema a un 70%. Algunos de nosotros hemos tenido la suerte de encontrar en algunos proyectos herramientas como Liquibase o Flyway, las cuales nos permiten llevar un control versionado de nuestros cambios en la base de datos. Pero aún así, no te permite ver el modelo completo de datos de forma sencilla.
Fueron estas razones las que me llevaron a intentar buscar alguna herramienta que, de forma rápida, me permitiera crear una documentación interactiva sobre mi base de datos.
Qué vas as ver en esta entrada
¿Qué es SchemaSpy?
Podríamos definir SchemaSpy como una herramienta realizada en Java que escanea los metadatos de tu base de datos y crea una representación visual en HTML de la misma, en la que de forma interactiva puedes navegar a través de sus relaciones, tablas, índices, etc.
Os dejo algunos enlaces de interés:
- Página principal de Schema Spy
- Documentación de Schema Spy
- Repositorio de código SchemaSpy
- Repositorio de contenedores SchemaSpy
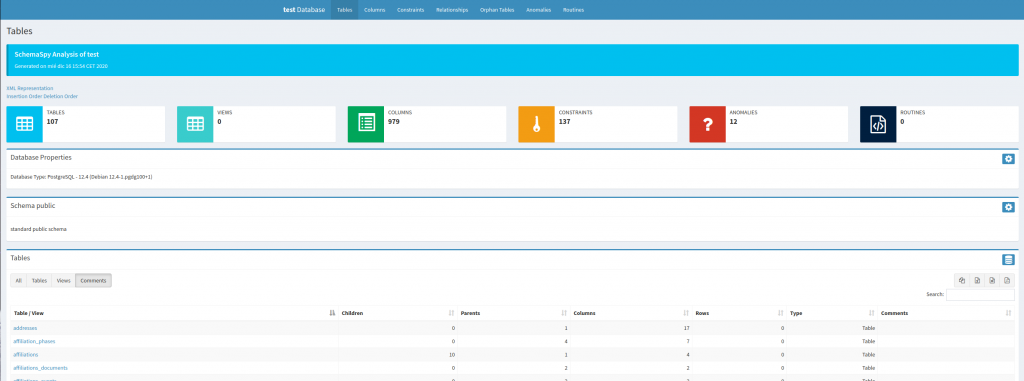
¿Qué información nos facilita?
- Información sobre las tablas: tablas padre, tablas hijas, volumetría, número de columnas, etc.

Haciendo click sobre cualquiera de ellas podemos acceder al listado de sus propiedades, índices, constraints, relaciones, etc.

- Información sobre vistas.
- Información sobre las relaciones entre tablas: En mi opinión esta es la posibilidad más potente que ofrece la herramienta, ya que nos genera al vuelo un diagrama entidad-relación de todas las tablas.

- Anomalías detectadas en la base de datos: como tablas sin índices, tablas sin clave foránea haciendo referencia a través de campos que se llaman iguales, etc.
- Información sobre tablas huérfanas.
- Información sobre procedimientos y funciones.
- Exportación de la información en pdf, excel, csv…
- Etc.
¿Cómo utilizar SchemaSpy?
Independientemente de si usamos el JAR directamente o a través de contenedores Docker, existen dos formas de utilizar la herramienta:
- A través de parámetros.
- A través de un fichero de configuración.
Para el siguiente ejemplo, usaremos su modo standalone (el JAR), el cual podemos descargar en esta dirección. Aunque la documentación indica que a partir de la versión 6.1.0 no es necesario instalar Graphviz , para el ejemplo he tenido que instalarlo.
Para facilitar la creación de una base de datos que nos ayude a enseñar la herramienta en su totalidad, hemos utilizado el siguiente esquema. En el ejemplo, hemos levantado una PostgreSQL mediante Docker con el siguiente comando:
docker run --name postgres-test -e POSTGRES_PASSWORD=test -e POSTGRES_USER=test -e POSTGRES_DB=test -p 5432:5432 -d postgres
Una vez tenemos creada nuestra base de datos y hemos ejecutado el script anterior para la creación del esquema completo, podemos proceder a utilizar SchemaSpy.
A través de parámetros
java -jar schemaspy-6.1.0.jar -t pgsql -dp postgresql-42.2.12.jar -host localhost -port 5432 -s public -u test -p test -o output -db test
- -t: Tipo de base de datos. Utilizando el comando -dbhelp obtenemos el listado completo de base de datos soportadas.
- -dp: Driver.
- -host: Host donde la base de datos está hospedada.
- -port: Puerto de conexión de la base de datos
- -s: Esquema de la base de datos al que conectarnos.
- -u: Usuario de la base de datos.
- -p: Password de la base de datos.
- -o: Carpeta donde queremos que SchemaSpy nos genere el reporte.
- -db: Nombre de la base de datos.
A través de fichero de configuración
# Database Type schemaspy.t=pgsql # Path Database JDBC driver schemaspy.dp=postgresql-42.2.12.jar # Database Machine schemaspy.host=localhost schemaspy.port=5432 # Database user schemaspy.u=test schemaspy.p=test # Database Name schemaspy.db=test # Database Schema schemaspy.s=public # Path output folder for the generated result schemaspy.o=output
Si no le indicamos ninguna ruta, la librería de SchemaSpy busca el fichero de configuración en la misma ruta que el jar. Si queremos indicarle una ruta alternativa, lo hacemos de la siguiente forma:
>java -jar schemaspy-6.1.0.jar -configFile config/schemaspy.properties

Conclusiones
De una forma tan sencilla como realizar una ejecución de una librería indicando los parámetros de conexión de la base de datos, podemos tener toda la información de una forma muy visual e interactiva.
También podremos identificar anomalías en nuestra base de datos o ciertos patrones de lógica de negocio a través de las propias restricciones de los campos, tener siempre la última imagen del estado de la base de datos, etc.
Y vosotros, ¿seguiréis sin documentar vuestra base de datos y teniendo que “adivinar” el modelo de datos de los proyectos?


