
La actual adopción generalizada de las arquitecturas basadas en microservicios ha estado motivada, entre otros factores, por el conjunto de beneficios y buenas prácticas derivadas de su aplicación. Aspectos como la modelización del negocio siguiendo los principios del domain-driven design (DDD) han recuperado la relevancia perdida durante el reinado de las arquitecturas monolíticas, devolviendo el foco a lo verdaderamente importante en el desarrollo de software: la modelización y resolución óptima de los problemas de negocio.
Sin embargo, a pesar del profundo cambio tecnológico y conceptual que ha supuesto este paradigma, la transición por lo general no ha sido completa. Continuamos trabajando con sistemas fuertemente acoplados que se comunican mediante llamadas HTTP y que generan dudas acerca de cómo resolver nuevos problemas como la gestión de la transaccionalidad inter-servicio. Todo esto ha hecho necesarias herramientas como Istio para dar solución a los inconvenientes propios de esa forma de integración.
En este momento podemos vislumbrar la próxima generación de arquitecturas de microservicios como aquella verdaderamente orientada a eventos de negocio. Se empieza a ver ya en la industria este giro, en el que los agregados internos a los bounded context responden de manera desacoplada a un flujo continuo de datos de negocio.
El motor de este cambio será el conjunto de tecnologías que han alcanzado la madurez necesaria para su adopción en entornos empresariales. Por una parte, disponemos de plataformas de programación reactiva como Spring Webflux o RXJava, de las que ya hablamos anteriormente, que si bien siguen ligadas a comunicaciones request/response, orientan dicha interacción a la simulación de la mensajería asíncrona usando las capacidades de IO no bloqueante de los servidores de aplicaciones. Por otra, nos encontramos con el API central de este artículo: Kafka Streams
Introducción a Kafka Streams
Kafka Streams es una librería de procesado de flujos de datos sobre Apache Kafka. Su release inicial se remonta a 2016, pasando desde ese momento a ser adoptada por numerosas compañías como The New York Times, Pinterest o Zalando.
Al estar construida sobre Apache Kafka, esta API nos permite construir aplicaciones con arquitecturas realmente orientadas a eventos, a la vez que aprovechamos sus capacidades subyacentes como la escalabilidad, con órdenes de magnitud en torno al millón de mensajes procesados por segundo, y tolerancia a fallos, a través del particionado de topics y su replicación en los miembros del clúster.
En la actualidad contamos con gran número de herramientas para implementar tareas de procesado de streams en tiempo real, siendo Spark la más destacada. ¿En qué se diferencia entonces y qué aporta Kafka Streams?
En primer lugar hay que poner de relieve su simplicidad. El objetivo inicial de los ingenieros era definir un API sencillo que proporcionara una manera directa e intuitiva de programar aplicaciones dirigidas por eventos, sin estar ligadas al procesado masivo de datos. Si nos fijamos en cómo se aborda el problema del procesado de streams desde la perspectiva del Big Data nos damos cuenta que se reduce a la distribución de una serie de tareas sobre un clúster de máquinas. Sin embargo, Apache Kafka opta por el enfoque contrario, donde la lógica de negocio de la aplicación embebe el procesado de los streams. Esto nos capacita para modelar el negocio de las empresas de una manera mucho más natural y realista, como lo que realmente es: un flujo continuo de eventos. A continuación vamos a ver un ejemplo de una aplicación de este tipo.
Monitorización en tiempo real de las estaciones de bicicletas de la Comunidad de Madrid (BiciMAd) con Kafka Streams
Uno de los factores diferenciadores de Kafka Streams es su capacidad para integrar el procesado de streams de datos en aplicaciones con estado. Esto conlleva el reto de enfrentar los requisitos de alto rendimiento de procesado con las latencias de acceso al estado actual de la aplicación, tradicionalmente contenido en bases de datos con comunicación bloqueante. Kafka Streams soluciona este problema a través de la dualidad stream-tabla, materializando los datos en almacenes locales contenidos en RocksDB y permitiendo realizar joins y agregaciones entre los flujos de mensajes (KStream) y sus materializaciones (KTable) sin penalizar el rendimiento.
En este post vamos a implementar un microservicio que se sirve de los elementos anteriores para monitorizar en tiempo real el estado de todas las estaciones de BiciMAD, el sistema público de alquiler de bicicletas de la Comunidad de Madrid. El código completo está disponible en Github.
El punto de entrada de nuestra aplicación es el topic STATIONS_TOPIC, donde se publican los eventos de actualización del estado de las estaciones de alquiler. En una implementación real, las estaciones serían las encargadas de publicar dichos eventos. Para este ejemplo lo simularemos a través de un timer que consulta el API de BiciMAD cada minuto y publica el estado de las estaciones en el topic:
A partir de la información del topic procesaremos los logs para obtener los siguientes elementos en tiempo real:
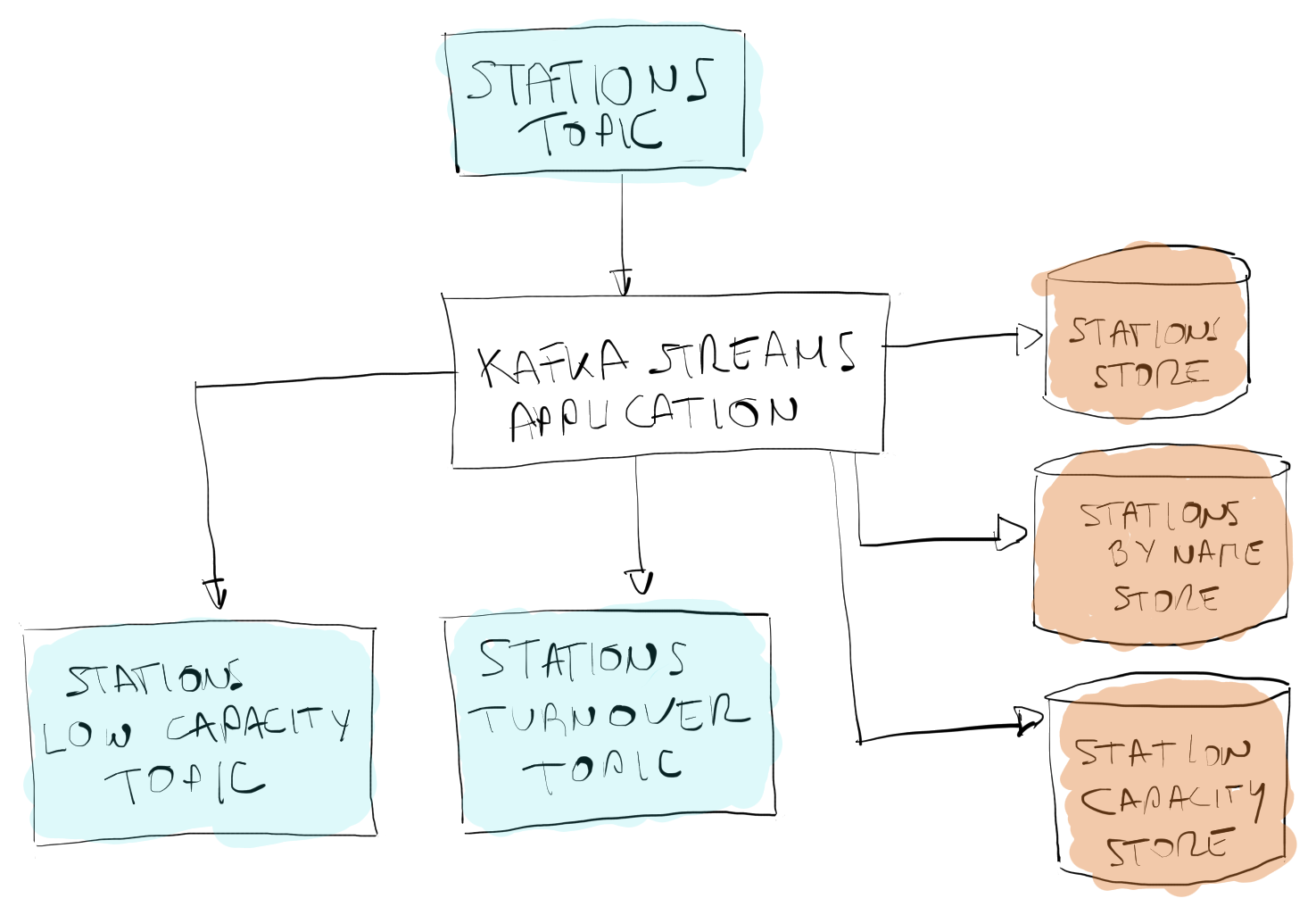
- Topics con métricas que responden a eventos de negocio:
- STATIONS_LOW_CAPACITY_TOPIC: informa sobre las estaciones con una capacidad inferior al 10%, calculada como bicicletas disponibles / capacidad total de la estación.
- STATIONS_TURNOVER_TOPIC: recoge la métrica de volumen de negocio (retirada y entrega de bicicletas) por estación en ventanas de una hora.
- Stores con el estado actual:
- STATIONS_STORE: estaciones indexadas por id.
- STATIONS_BY_NAME_STORE: estaciones indexadas por nombre.
- STATIONS_CAPACITY_STORE: relación completa de estaciones y su capacidad
Antes de comenzar, definiremos los objetos Serde en los que nos apoyaremos para serializar y deserializar los mensajes en formato JSON:
A continuación construiremos la topología completa de procesado de la aplicación sirviéndonos de la clase StreamBuilder.
En la primera rama de la topología canalizamos los mensajes de STATIONS_TOPIC en un KStream, lo agrupamos por clave (id de la estación) y realizamos una reducción trivial para convertir el flujo en una KTable y materializarla en el store STATIONS_STORE. Continuaremos convirtiendo nuevamente el flujo en un stream, filtrando las estaciones con capacidad menor al 10% y publicando un objeto resumen, BiciMadStationStats, en el topic STATIONS_LOW_CAPACITY_TOPIC.
En la siguiente rama se muestra un procesado simple que genera un store actualizado en tiempo real con el total de estaciones y su capacidad. Para ello se hace una operación mapValues que transforma cada estación en un valor double con su tasa de disponibilidad, las agrupa por clave y las materializa en el store STATIONS_CAPACITY_STORE:
En la tercera rama de la topología tenemos un ejemplo de reparticionado de un topic, es decir, la redistribuición de un stream seleccionando una nueva clave, con lo que podremos generar un store indexado por nombre de estación en vez de por id (STATIONS_BY_NAME_STORE).
La última rama recoge un flujo más complejo, en el que se busca determinar el volumen de negocio de cada estación en ventanas de una hora. Para ello empezamos agrupando el stream por clave y estableciendo la ventana de procesado. El siguiente paso consiste en realizar una agregación en la que calculamos el cambio neto en número de bicicletas de la estación, obtenido como el valor absoluto de la diferencia entre las bicicletas presentes previamente en la estación y las informadas por el mensaje actual. Finalmente, mediante una operación mapValues, calculamos el volumen de negocio en porcentaje como el cambio neto dividido por la capacidad de la estación, escribiéndolo en el topic STATIONS_TURNOVER_TOPIC.
Conclusiones
En este artículo hemos podido ver lo sencillo que resulta implementar con Kafka Streams un microservicio con estado que realiza el procesado de mensajes en tiempo real.
No obstante, hay que tener en cuenta que determinados aspectos se han simplificado o se han obviado con el objetivo de poner el foco en la implementación de la lógica de negocio. Entre ellos hay que mencionar el particionado del topic de entrada, clave para conseguir el paralelismo de la ejecución. Relacionado con lo anterior, un sistema que quiera hacer consultas sobre un store particionado tendría que hacer uso de las remote interactive queries para poder agregar el contenido del conjunto de stores locales.


