
Qué vas as ver en esta entrada
¿Qué es web scraping?
La gran cantidad de páginas web que existen en la actualidad en Internet conforman un conjunto de información inmenso. El hecho de que la mayoría de las webs tengan acceso público hace que los usuarios puedan extraer no solo datos, sino conocimiento.
Muchas veces las páginas permiten la descarga de la información mediante algún formato de archivo exportable o publicando la información en una API, incluso hay iniciativas que fomentan la compartición de datos entre el público general. Por ejemplo, en https://datos.gob.es/ existe un amplio catálogo de descargas de todas las administraciones públicas españolas.
Sin embargo, muchas veces no existe una descarga directa de los datos, sino que la información únicamente se muestra en la estructura y contenidos de la propia página web. ¿Y qué podemos hacer en estos casos? Efectivamente, web scraping, que no es más que la obtención de información a partir de páginas web que se encuentren disponibles en Internet.
¿Por qué usarlo?
Principalmente, para explotar información a la que no se tiene acceso si no es mediante las páginas web. Veamos algunos casos (algunos menos bienintencionados que otros):
- Agrupar datos de diferentes webs para construir información conjunta.
Por ejemplo, con la pandemia de COVID muchas personas han recopilado los datos de contagios de las comunidades autónomas y han compartido diferentes visualizaciones.
Otro ejemplo podría ser una web que venda electrodomésticos de múltiples tiendas online. Para obtener algunos precios podría ser necesario consultar la página web de una tienda en concreto.
- Obtener información de la competencia.
Continuando con la web de venta de electrodomésticos, nos podría interesar comparar los precios con los de otras tiendas online, y así adaptar los precios, ofertas o estrategias para mejorar las ventas.
- Obtener información de webs.
Algunas veces el organismo, empresa o responsable de una página web no puede asumir los costes de incluir un área de descargas o un API, o simplemente no le interesa. En estos casos, nos puede interesar extraer la información para tratarla después.
- Incluso se podría utilizar para hackear, aprovechando los agujeros de seguridad de las webs.
Imaginemos que la tienda online de electrodomésticos tiene una zona donde el cliente se puede registrar para consultar sus pedidos o realizar reclamaciones. Para hacerlo, tiene que introducir su email y una contraseña.
Si el formulario de acceso devuelve una respuesta diferente en los casos en que el cliente no está registrado, o cuando está registrado pero se confunde de contraseña, se podrían obtener todos los emails dados de alta en la tienda de electrodomésticos.
Problemas al hacer web scraping
Hasta ahora hemos ido enumerando las bondades y beneficios de hacer web scraping, pero es evidente que los administradores de la web no lo ponen tan sencillo.
Indicamos a continuación varios problemas que pueden darse al intentar extraer información:
- Modificación de la estructura de las webs.
Las páginas se encuentran en constante cambio, no solo de contenidos, sino que también de la estructura o el diseño. La extracción de información no es bidireccional entre el scraper y la administración de la web, por lo que la persona o entidad que desee obtener los datos debe estar al tanto de los posibles cambios que se vayan produciendo en las páginas.
Puede haber cambios en la estructura que rompan el proceso que se encarga de obtener los datos, y también nuevas secciones que incluyan más información (o la eliminen).
- Bloqueos de las páginas web.
A la competencia no le interesa que obtengamos ventaja de sus publicaciones, por lo que, si detecta que alguien está accediendo a su web con el objetivo de extraer información, lo más normal es que bloquee esas llamadas, bien sea porque el origen es un robot, o hay llamadas sospechosas por producirse de manera periódica.
Además, algunas técnicas pueden resultar bastante agresivas en cuanto al número de llamadas en un corto espacio de tiempo, y se pueden producir caídas de los servidores.
Para prevenir posibles bloqueos, existen técnicas como la modificación del user agent de las peticiones, la distribución de las llamadas en el tiempo, o sortear las posibles trampas que haya en el código que hagan más difícil el cometido de obtener información.
- Aspectos legales y éticos.
Como en todo, siempre nos podemos topar con la ley, impidiendo completar nuestros objetivos.
Si una web indica en sus términos y condiciones que no se puede realizar scraping, y además pide aceptación explícita al usuario, no se podrá realizar legalmente la extracción de datos. O a la hora de incumplir con las licencias que tenga la página web.
Varias leyes para tener en cuenta serían los reglamentos sobre competencia, uso de información personal o las diferencias geográficas.
Pero no debemos olvidar que muchas veces, más allá del cumplimiento estricto de la ley, se deberían tener en cuenta una serie de condiciones éticas. Entre otras, seguir las recomendaciones del archivo robots.txt.
- Elevada información.
Muchas veces puede ser un reto elegir qué datos nos interesan de toda la estructura de páginas de una web. No es eficiente ni útil obtener toda la información que está publicada.
¿Cómo hacer web scraping?
El scraping se debe realizar a partir del DOM (Document Object Model) de la web elegida, por lo que se debe estar familiarizado con esta estructura jerárquica.
El primer paso es investigar cómo está organizada la web, localizar las secciones que son de nuestro interés, cuáles son las tecnologías que han utilizado para su construcción, y hasta qué punto se puede realizar la extracción de datos teniendo en cuenta los motivos legales y éticos.
Una vez localizadas las secciones que nos interesan, se debe inspeccionar el código para detectar cuáles son los elementos donde se incluyen los datos. De esta manera, se podrá aplicar una estrategia para poder extraer la información.
Por ejemplo, imaginemos que vamos a realizar web scraping en este blog de Profile, concretamente queremos obtener todos los artículos del blog. Por lo tanto, lo primero que tenemos que hacer es acceder con nuestro navegador a la dirección https://profile.es/blog/.
Se puede ver que la página tiene la siguiente estructura:
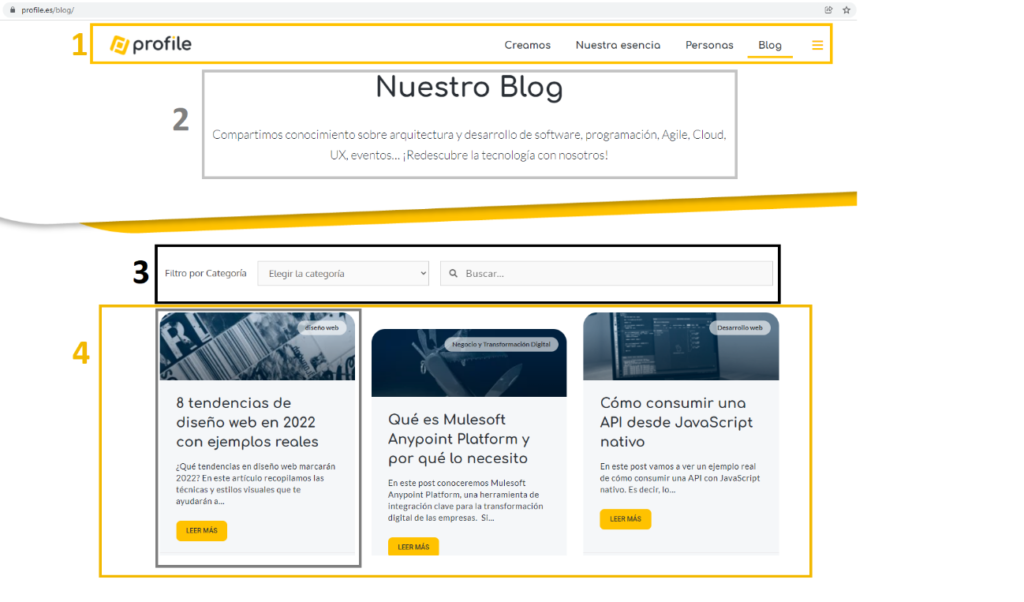
- Cabecera, con el menú de la web.
- Título de la página.
- Filtro de búsqueda, bien sea por categoría o contenido.
- Artículos del blog, con título, imagen, categoría, extracto, fecha y enlace al detalle.
Nos vamos a centrar en obtener los atributos que acabamos de listar de cada artículo, por lo que, si inspeccionamos el código con nuestro navegador web, podemos ver que los artículos se muestran dentro de un div cuya clase es “elementor-posts-container”, y que cada uno de los artículos tiene la clase “elementor-post”.
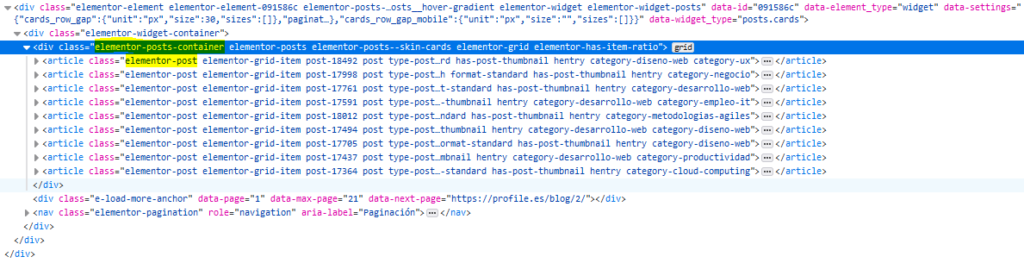
Para poder obtener la información de los artículos, también deberemos inspeccionar cómo se estructuran.
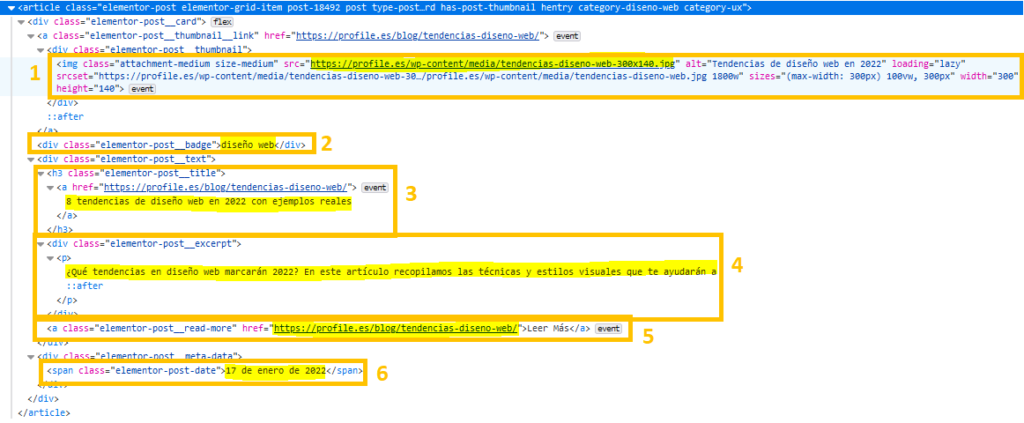
Los 6 atributos se muestran de la siguiente manera:
- Imagen: en el atributo src de la imagen del div “elementor-post__thumbnail”.
- Categoría: en el div con clase “elementor-post__badge”.
- Título: como contenido del enlace bajo el título h3 con clase “elementor-post__title”.
- Extracto: como contenido del párrafo que está dentro del div con clase “elementor-post__excerpt”.
- URL del detalle del artículo: en el atributo href del enlace con clase “elementor-post__read-more”, aunque se puede obtener esta URL de otros dos puntos diferentes.
- Fecha. Como contenido del span con clase “elementor-post-date”.
El blog tiene una parte de paginación, por lo que para cargar todos los artículos del blog se deben recorrer todas las páginas.

Mejores herramientas de web scraping
Existen múltiples formas de realizar scraping, comenzando con programas de software que permiten a los usuarios menos técnicos configurar los datos que se quieren obtener de una página concreta o incluso permitir al programa la extracción automática de la información más relevante de la web. Varios ejemplos son:
- Scrapestack: https://scrapestack.com/.
- Apify: https://apify.com/.
- Webscraper: https://webscraper.io/.
Por otro lado, los desarrolladores de software podemos utilizar librerías de algunos lenguajes de programación para sacar todo el partido posible a las webs. Entre otros lenguajes, podemos utilizar:
- Node.js, con Axios o SuperAgent.
- Python, con BeautifulSoup o Scrapy.
Web Scraping con Python
Vamos a realizar un ejemplo con Python3 y las librerías Request y BeautifulSoup.
En primer lugar, Requests sirve para realizar peticiones HTTP de todos los métodos como GET, POST o PUT de una manera sencilla.
BeautifulSoup es una librería que se utiliza para obtener el árbol del contenido de una URL determinada o un fragmento de código HTML, y dispone de funciones para poder navegar por todos los elementos y realizar búsquedas sobre los mismos.
Para comenzar, se deben obtener las librerías y realizar su importación:
# Instalación de librerías pip3 install requests pip3 install beautifulsoup4 # Imports de las librerías import requests from bs4 import BeautifulSoup
Lo siguiente que se debe hacer es descargar la página web, que haremos mediante una petición GET a https://profile.es/blog con la librería requests.
URL_SCRAP = 'https://profile.es/blog' response = requests.get(URL_SCRAP)
Obtendremos un objeto de tipo Response (https://www.w3schools.com/python/ref_requests_response.asp), del que podemos utilizar dos propiedades interesantes:
- status_code, con el estado de la respuesta, que será 200 en caso de que hayamos recibido la respuesta correctamente.
- content, con el contenido de la respuesta.
Siempre que obtengamos una respuesta correcta, deberemos construir un objeto de la clase BeautifulSoup, pasando como argumento el content de la respuesta obtenida.
if response.status_code == 200:
bs_response = BeautifulSoup(response.content)Este objeto es el que nos permitirá navegar en la estructura anidada de la página. Podemos utilizarlo de diferentes maneras:
- Accediendo a los elementos de manera anidada. El objeto bs_response contiene un atributo por cada uno de los elementos obtenidos de la página web. Por ejemplo, si se quiere acceder al body, se tendrá que usar “bs_response.body”.
- Utilizando funciones que permitan buscar mediante una serie de filtros, de una manera similar a como lo hace jQuery con los filtros. Entre las funciones más utilizadas están find_all (devuelve todos los objetos que se corresponden con el filtro) o find (devuelve el primer objeto encontrado).
Para finalizar os dejamos el código de la realización de web scraping de los artículos del blog de Profile que hemos analizado previamente: https://github.com/vicpari89/web-scraping/.


